Notizen über Recherche, Daten, KI und Geschichte
Mit ChatGPT am Krankenbett.
Da liegst du nichtsahnend im Krankenhaus, hast deine Daten und Gebrechen zehn Mal ins gleiche Papier-Formular eingetragen - und dann kommt der Arzt rein und hackt deinen Leidensweg samt Befunde in ChatGPT.
Macht keiner? Oh doch!
In Deutschland nutzen rund 30% der Ärzte ChatGPT und Co. zu Dokumentationszwecken (Doctolib 2026 / Konnerth et al. 2025). In den USA schreiben über 20 % der Studierenden klinische Notizen damit (Xu et al., 2025). Und in Frankreich gibt mehr als die Hälfte an, im Praktikum generative KI zu nutzen. Ein Viertel hatte bereits Patientendaten in ChatGPT eingegeben. Dabei waren nicht mal 5% für den KI-Einsatz ausgebildet (Kotzki et al., 2026).
Genau diese Lücke zwischen KI-Ausbildung im Medizinstudium (niedrig bis nicht existent) und KI-Nutzung in der Praxis (ziemlich hoch) gibt es weltweit. Im DACH-Raum nutzten laut einer Umfrage 76% der Medizinstudierenden ChatGPT. Eine formale KI-Ausbildung hatten 5% erhalten, von KI-Ethik hatten 4 % was gehört. Kein Wunder, dass 75-85% mit ihrer Ausbildung in diesem Bereich unzufrieden sind (Weidener & Fischer, 2024 / Tolks & Keller 2024).

Das Muster zieht sich durch. Fast überall auf der Welt haben (angehende) Mediziner kein oder kaum ein formales KI-Training erhalten, trotzdem wird KI in vielen Kliniken genutzt. Viele berichten dabei von einem Verfall des kritischen Denkens (Alazzawi & Lam, 2026 / AlAlwan & Lone, 2026).
Eine Studie aus Marburg zeigt, dass intensive ChatGPT-Nutzung mit höherem Vertrauen in KI-Outputs assoziiert ist (Fußhöller et al., 2025). Das Wissen über Bias und Grenzen von KI-Systemen bleibt derweil gering. Dabei gibt es gute Ansätze: Ein Kurs an der Uni Mainz führte dazu, dass Studierende differenziert und kritisch mit generativer KI umgingen. (Oftring et al., 2025).
Doch das sind Ausnahmen, auch wenn immer mehr Medizinfakultäten KI-Angebote haben. Gleichzeitig sagen aber die meisten Studierenden, sie würden keine oder keine gute KI-Bildung erhalten. Der Grund: Vieles läuft (noch) als Wahlfach oder Zusatzformat, das sich nur schwer in die hohe Studienbelastung integrieren lässt. Dazu kommen fehlende Lehrkapazitäten sowie die Vorgaben der Approbationsordnung und des Kompetenzbasierten Lernzielkatalogs, die strukturell ziemlich träge sind – ganz im Gegensatz zu den Medizinstudenten und Ärzten, die ChatGPT zur Dokumentation nutzen und Befunde und Patienteninformationen mehr oder weniger ungeschützt in die KI hacken.
Klar, das machen nicht alle, ein Teil nutzt lokale, DSGVO-konforme Systeme und anonymisiert die Daten ordentlich. Aber ChatGPT und Co wirken auf viele verführerisch. Auch in der Forschung. Medizinjournale berichten über einen massiven Anstieg halluzinierter Quellen in den Papers. Das könnte ein Hinweis sein, wie verbreitet Schatten-KI-Nutzung inzwischen ist.
Während du also zum 11. Mal denselben Anamnesebogen ausfüllst, sitzt im Hintergrund vielleicht längst generative KI mit am Krankenbett...
Bild: Freepik, mit KI editiert.
28. Mai 2026
KI-Recherche mit Asta: Literatur finden, Berichte erstellen, Daten analysieren - alles komplett kostenlos.
"There ain’t no such thing as a free lunch" lautet ein Sprichwort, aber bei der Recherche trifft das nur bedingt zu, denn es gibt durchaus freie Tools, auch wenn ich die versteckten Kosten von KI nicht kleinreden will. Aber wie dem auch sei, "Asta" ist jedenfalls frei zugänglich und komplett kostenlos nutzbar. Der Name steht übrigens in diesem Fall nicht für "Allgemeiner Studierendenausschuss", sondern für "Ai2 Scholarly Task Assistant". Die dazugehörige Plattform wird vom Allen Institute for AI entwickelt. Das sind die, die auch Semantic Scholar bauen, auf dem wiederum Asta aufbaut.
Aber zur Sache: Mit Asta kann man drei Dinge machen:
1.) mit Hilfe von KI Literatur suchen
2.) Zusammenfassungen zu einem Thema erstellen und
3.) Daten auswerten.

Für die ersten beiden Funktionen kann man auf 108 Mio. Abstracts und 12 Mio. Volltexte zurückgreifen. Das ist - verglichen mit anderen Tools - zwar eher unterer Durchschnitt, aber dafür bietet Asta qualitativ einiges, denn es nutzt eine mehrstufige Retrieval-Pipeline, die die Suchanfrage in Einzelteile zerlegt, die Relevanz der Treffer gewichtet, Evidenzpassagen aus den Studien extrahiert und anschließend erklärt, wie gut ein gefundenes Paper zur Frage passt (perfectly relevant / relevant / somewhat relevant).
Die entsprechenden Belegstellen aus den Texten werden genannt und die Verarbeitungsschritte der KI dokumentiert, sodass alles überprüfbar ist.
Wer mehr wissen will, kann sich statt Treffer zu einem gewünschten Thema einen Report ausspucken lassen, wobei der Bericht in Kapitel untergliedert und jedes Kapitel mit mind. zwei Quellen versehen wird. Das ist solide, auch wenn Asta - wie allen KI-Tools - die üblichen Bias eingeschrieben sind:
- primär englischsprachige Paper
- meist Studien, kaum Bücher
- wenige "graue Literatur"
Aber in einem guten Recherche-Workflow gibt's genug Anlaufstellen, um diese Lücken zu füllen. Insofern ist das kein wirklicher Mangel, sondern Teil der Geschichte. (Beim free lunch kann man schließlich nicht noch Nachtisch erwarten :))
Wer neben der Recherche noch Daten analysieren will, kann das ebenfalls tun. Einfach Excel- oder andere Datei henochladen, Frage stellen - schon werden die Ergebnisse zusammengefasst und visualisiert. Natürlich gibt es für die Datenanalyse elaboriertere Tools wie julius.ai, aber für den Alltagsgebrauch genügt (mir) Asta durchaus.
Apropos: aktuell wissen wir noch sehr wenig, wie KI-Recherche-Tools im Alltag eingesetzt werden. Bei Asta wurde das in einer Studie anhand von 258.000 Anfragen empirisch erfasst (Link). Dabei zeigt sich, dass die Nutzer zwischen Quellen und Antworten hin und her springen und die KI zunehmend als (agentischen) Forschungsassistenten statt als reine Suchmaschine verwenden.
So, wer jetzt auf den Geschmack (des free lunch) gekommen ist, einfach hier entlang:
https://asta.allen.ai/
Guten AI-ppetit! 😉
18. Mai 2026
KI-Recherche-Tools werfen mit Millionen Dollar, riesigen Kooperations-Verträgen und Dutzenden neuen Features um sich - und in Deutschland scheint's keiner zu merken.
Entweder ist mein LinkedIn-Feed schizophren oder in der deutschen KI-Hochschul-Wissenschaft-und-Bibliotheks-Blase hat wirklich kaum einer mitbekommen, wie schnell und tiefgreifend die Veränderungen beim Thema Recherche gerade vonstatten gehen. Im Grunde wird momentan eine der zentralen Schnittstellen zur Wissenschaft neu gebaut - und das, was wir bisher Daten- und Literaturrecherche genannt haben, wird dabei komplett auf den Kopf (oder die Füße) gestellt.

Ich werde die generellen tektonischen Verschiebungen ein ander Mal ausführlich behandeln, hier und jetzt geht's mir erstmal darum, die neue Recherche-Welt und ihre Dimensionen auf der Tool-Ebene zu skizzieren. Dabei genügt ein Blick auf Consensus (Link). Die haben gerade 30 Mio. Dollar neues Kapitel eingesammelt und schließen mit immer mehr großen Wissenschaftsverlagen Kooperationen. Wiley und Sage waren schon am Start, heute kam Taylor & Francis dazu, weitere folgen. Aber nicht irgendwie, sondern mit Volltexten.
Bisher haben die meisten KI-Tools nur die Abstracts und Metadaten durchrastert, jetzt geht's zunehmend tief und komplett rein in die Daten und Literatur. Dazu kommen mehrstufige Recherche-Agenten, komplexe Analysen von Zitationsnetzwerken, und immer mehr Funktionen, die weit, weit über die Recherche hinausführen. Achja, Direktverbindungen zu ChatGPT und Claude haben viele Tools inzwischen auch.
Die Folge: Die Nutzerzahlen steigen rasant, nicht nur bei Consensus, sondern bei fast allen der rund 50 KI-Recherche-Tools, die es aktuell für den Wissenschaftsbereich gibt. Immer mehr Hochschulen und Bibliotheken experimentieren damit, testen die Tools und erwerben Lizenzen für ihre Studis und Forscher. Nur in Deutschland nicht. Da gründet man lieber einen Arbeitskreis KI und wundert sich, dass die Studierenden ihre Recherchen (und Hausarbeiten) mit ChatGPT erledigen.
Dabei gibt es auch hierzulande wunderbare Tools wie scienceOS.ai (Link). Wie es überhaupt viele tolle Tools zu endecken gibt, wenn man mal die Konzeptschreiberei lässt und sich ins Machen stürzt. Denn nur so lernt und versteht man, was gerade passiert.
Gewiss, einige machen das. Aber es sind viel zu wenige. Meist beruhen die entsprechenden Fähigkeiten und Initiativen auf individuellem Engagement und sind institutionell nicht verankert.
Den meisten fehlt der Überblick über das, was gerade passiert. Auch ich komme kaum mehr mit. Aber das ist nicht schlimm. Schlimm ist, dass es viele nicht probieren, weil sie nach einer Ordnung und Übersicht suchen, die es einfach nicht mehr gibt, weil sie ein „richtiges“ Konzept, eine sichere Policy und ein offizielles Vorgehen wollen, statt sich offensiv mit dem Tempo und der Tiefe der Veränderungen auseinanderzusetzen.
Wir müssen verdammt nochmal wieder mutiger werden!
16. Mai 2026
Recherche auf Preprint-Plattformen mit KI. Ergebnisse eines Live-Praxistests von alphaXiv. Und ein überraschendes Ergebnis.
Ich habe gestern an der Technischen Universität Chemnitz einen Tagesworkshop zur Daten- und Literaturrecherche gegeben. Dabei habe ich live einen kompletten Workflow gezeigt: von Bibliothekssystemen über Fachdatenbanken (inkl solchen mit KI-Assistenten), weiter über akademische Suchmaschinen und Repositorien bis hin zu wissenschaflichen KI-Recherche-Tools und Programmen zum Citation-Tracking mit KI.
Auch Preprint-Plattformen waren natürlich ein Thema. Die KI-Integration ist hier noch nicht sehr weit, auch wenn Semantic Scholar einen Semantic Reader hat, der PDFs von arXiv mit KI analytisch leichter zugänglich macht. Am meisten beeindruckt hat mich aber alphaXiv. (Link)
Es ist ein Overlay über arXiv, greift aber auf weitere Datenquellen zu. Technisch läuft es über einen RAG-Ansatz mit agentischen, mehrstufigen Retrieval-Prozessen: Keyword Search, Vektorsuche, Abstract- und Volltext-Lesen, alles verbunden durch ein LLM, das nach verschiedenen Metriken rankt und dann eine Antwort erstellt.
Neben der Suche haben wir gestern live noch etwas getestet, nämlich die Möglichkeit, mit den Papers zu chatten. Ein Teilnehmer hatte einen Preprint aus dem Bereich Medizin dabei und vermutet, dass darin ein kleiner methodischer Fehler ist. Nichts Großes, aber einem aufmerksamen Reviewer würde es wahrscheinlich auffallen. Er wollte wissen: findet alphaxiv den Fehler?
Also haben wir es live getestet. Und siehe da: das Programm hat das Problem gefunden, die Stelle geflagged und auch eine Erklärung geliefert, warum die Methode an dieser Stelle problematisch ist.
Das zeigt mal wieder: KI-gestützte Recherche-Tools können oft viel mehr als einfach nur Literatur zu suchen, sondern Studien auf vielfältige Art und Weise analytisch durchdringen. Viele KI-Tools - wie z.B. SciSpace - sind inzwischen end-to-end konzipiert und decken den gesamten wissenschaftlichen Arbeitsprozess ab. Ob sich die den Preprint-Plattformen dahingehend entwickeln, glaube ich zwar nicht, aber auch hier ist KI inzwischen angekommen und erweitert die Möglichkeiten der Analyse.
Deshalb die Frage: Wer von euch hat alphaXiv schon mal getestet? Oder den mit arXiv verbundenen Semantic Reader in Semantic Scholar probiert?
Ich freue mich über Erfahrungen. Und eure Anmerkungen zur wissenschaftlichen Recherche - mit und ohne KI. Denn eines ist klar: die klassischen Bibliothekssysteme und Suchtechniken sind weiterhin nötig. Mehr als die meisten glauben, auch das haben die Teilnehmer gestern im Workshop gemerkt.
15. Mai 2026
Politische Entscheidungen zum Thema KI und Bildung beruhen oft auf Vermutungen, Wunschdenken und - schlecht gemachten Studien.
Fangen wir am Ende an: am 22. April wurde die wohl einflussreichste Metastudie zum Thema KI und Lernen zurückgezogen. Es handelt sich um Wang & Fan: The effect of ChatGPT on students’ learning performance, learning perception, and higher-order thinking: insights from a meta-analysis. (Link)
Das Paper wurde 2025 in den "Humanities and Social Sciences Communications" veröffentlicht und seitdem rauf und runter zitiert. Allein bei Google Scholar sind über 500 Zitationen vermerkt.
Die Metastudie von Wang & Fan untersuchte den Einfluss von ChatGPT auf die Lernleistung, Lernwahrnehmung und das höhere Denken von Schülern bzw. Studierenden anhand einer Analyse von 51 (mehr oder weniger) experimentellen Studien von 2022 bis 2025.
Ziel war es herauszufinden, ob ChatGPT tatsächlich positive Effekte auf Lernprozesse besitzt und unter welchen Bedingungen diese besonders stark auftreten. Laut Wang & Fan lieferte ChatGPT einen "large positive impact" auf Lernleistung und moderate Effekte auf Lernwahrnehmung und höheres Denkvermögen.

Warum die Studie zurückgezogenen wurde, geht es dem dürren Drei-Zeiler, der jetzt auf nature.com veröffentlicht wurde, nicht hervor. (Link)
ABER: Überraschend war die Rücknahme des Papers nicht. Zumindest nicht, wenn man sich die Forschung genauer angeschaut hatte.
František Bartoš et al. hatten nämlich im Januar 2026 insgesamt 67 solcher Meta-Analysen in Form einer Meta-Meta-Analyse neu ausgewertet. (Link)
Ich hatte damal darüber berichtet. (Link)
Der Befund von Bartoš et al.: Die Effekte der Meta-Studien sind verzerrt, weil die verwendeten Methoden nicht passend waren, weil Berichte über Effektstärken und moderierende Variablen fehlten und weil positive Ergebnisse generell häufiger eingereicht und häufiger zitiert werden.
Wang & Fan hatten Bartoš et al. dabei explizit im Blick, sprachen von einer möglichen Publikationsbias und suboptimalen methodische Entscheidungen, die die berichteten Effekte erheblich aufgebläht haben dürften.
Mit anderen Worten: Wir haben keine wirklich verlässlichen Daten zum Einfluss von KI auf Bildungs- und Lenrprozesse. Dafür haben wir umso mehr bildungspolitische Entscheidungen auf Basis von Vermutungen und Wunschdenken. Auf der einen Seite Horrorstories, auf der anderen Seite Heilsgeschichten. Und dazwischen eine Realität, die niemand so richtig kennt oder wahrhaben will.
13. Mai 2026
Die HalluCitations wachsen. Und wenn wir nicht aufpassen, wachsen sie uns über den Kopf und ziehen der Wissenschaft dabei die Füße weg.
Frisch aus "The Lancet", jener ebenso renommierten wie altehrwürdigen Medizin-Fachzeitschrift, die vor gut 200 Jahren vom umtriebigen Thomas Wakley gegründet wurde. Wakley hätte sich wahrscheinlich nicht mal zu halluzinieren gewagt, mit welchen Problemen sich sein Journal anno 2026 rumschlagen muss.
Die Ausgangslage:
Wissenschaftliche Literatur basiert auf der Integrität ihrer Referenzen. Halluzinationen, also von KI fabrizierte Referenzen, untergraben das Vertrauen in die Forschung und stellen eine reale Gefahr dar, gerade in der evidenzbasierten Medizin.
Bisher gab es keine systematische Überprüfung der Referenzintegrität in der biomedizinischen Literatur. Das hat die heute erschienene Studie von Maxim Topaz et al. geändert. (Link)
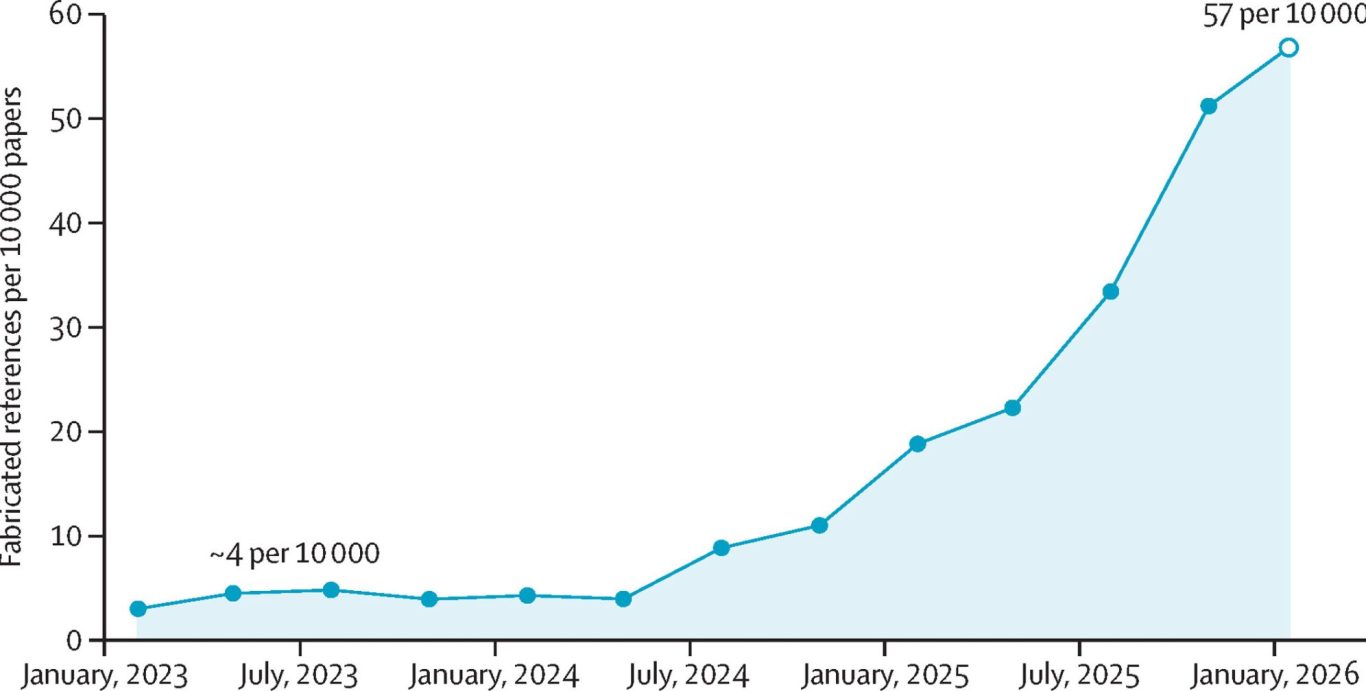
Die Datenbasis:
2.471.758 Papers aus PubMed Central Open Access von Januar 2023 bis Februar 2026. Insgesamt 125.615.773 strukturierte Referenzen, davon 97,1 Mio. mit PubMed-ID verifiziert und näher untersucht. (Der Rest war graue Literatur etc. und wurde ausgeschlossen.)
Der Verifikationsprozess:
Automatisierte Abgleichung: Vergleich der Referenzmetadaten, Filterung von False Positives, um Formatierungsfehler zu erkennen usw.
Das Ergebnis:
4.046 fabrizierte Referenzen in 2.810 Papers. Und das waren peer-reviewte Papers. Das heißt: an weniger strengen Publikationsorten ist das Problem wahrscheinlich noch deutlich größer.
Besonders erschreckend ist der zeitliche Anstieg. Der Anteil an Papers mit mind. einer Halluzination betrug 2023 noch 1 von 2.828 Papers. Anfang 2026 fanden sich dagegen schon in 1 pro 277 Papers fabrizierte Referenzen. Das macht 57 HalluCitations auf 10.000 papers. (siehe die Grafik).
Das heißt: zwar waren 98,4% der untersuchten Papers (noch) sauber, aber der Trend geht in keine gute Richtung.
Liegt das "nur" an den LLMs? Welchen Anteil haben Paper Mills und einzelne Akteure? (relativ viele Halluzinationen stammten von einer eher kleinen Gruppe von Autoren). Gibt es organisierte Fälschernetzwerke? Und wie viel ist Absicht, wie viel einfach nur "KI-Dummheit"?
Über all das wird zu diskutieren sein. Fakt ist, in anderen Bereichen der Wissenschaft sind die Zahlen ähnlich.
In meinen KI-Workshops an Hochschulen merke ich, das bei vielen noch das Problembewusstsein fehlt, wie groß die Halluzinations-Gefahr ist. Auch und gerade bei studentischen Arbeiten. Aber eben längst mehr nicht nur da.
Es ist Zeit, für eine umfassende KI-Bildung für alle Akteure im wissenschaftlichen Bereich.
12. Mai 2026
Workshop: Visualisierung mit KI in der Lehre:
Wissenschaft darstellen, erklären und kommunizieren. Für Dozentinnen und Dozenten sächsischer Hochschulen.
Visualisierungen werden immer wichtiger, auch in der Hochschullehre.
Infografiken, Statistiken, Diagramme und andere Formen der Darstellung strukturieren komplexe Inhalte, unterstützen das Verständnis und sind wichtige Bestandteile einer guten Wissenschaftskommunikation.
Mit KI-gestützten Tools stehen Lehrenden ganz neue Möglichkeiten zur Verfügung, Visualisierungen schnell, flexibel und qualitativ hochwertig zu erstellen.
In Zusammenarbeit mit der Hochschuldidaktik Sachsen führe ich deshalb am 16. September 2026 an der Universität Leipzig einen Workshop zum Thema "Visualisierungen mit KI in der Lehre" durch.
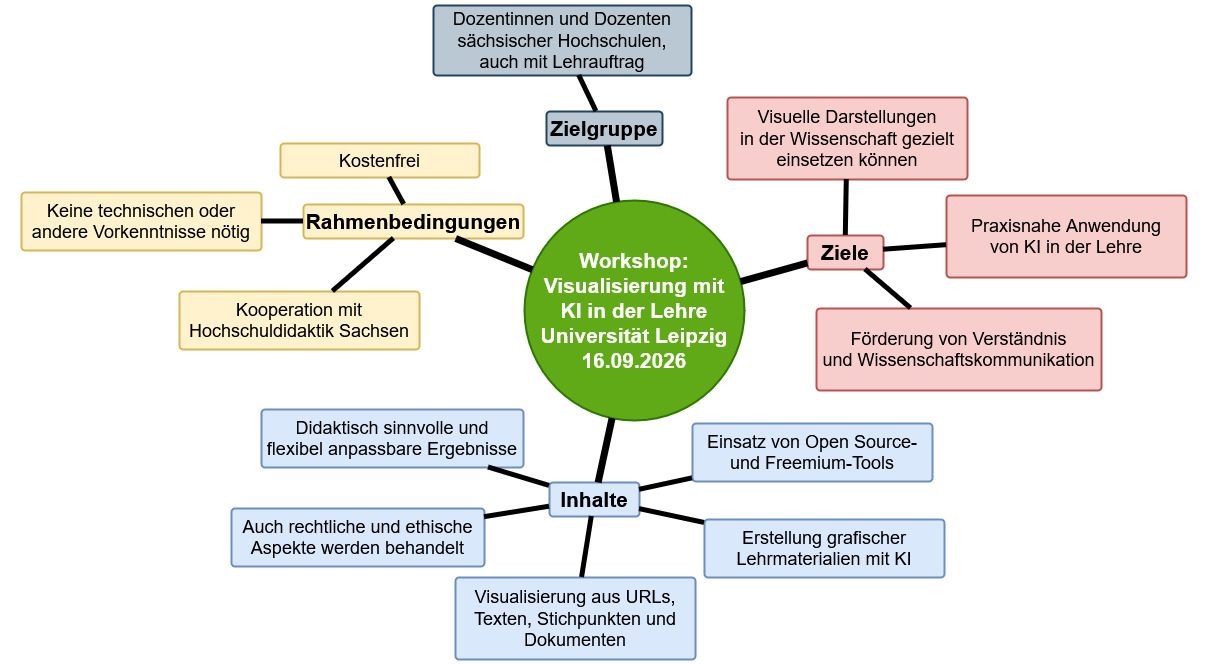
In dem Workshop zeige ich praxisnah, wie Sie mit KI grafische Lehrmaterialien erstellen und Lernprozesse gezielt unterstützen können. Die Teilnehmer lernen aus Texten, Stichpunkten, URLs oder Dokumenten didaktisch sinnvolle Grafiken und Videos zu generieren.
Dabei steht nicht das schnell erzeugte Bild im Vordergrund, sondern Ergebnisse, die sich flexibel weiterbearbeiten und gezielt an die eigenen Anforderungen in der Lehre anpassen lassen.
Auch rechtliche und ethische Aspekte bei der Erstellung von KI-gestützten Darstellungen werden thematisiert.
Die im Kurs vorgestellten KI-Tools sind entweder Open Source oder bieten großzügige Freemium-Modelle, sodass sie für den Einstieg vollständig kostenlos genutzt werden können.
Für die Teilnahme sind keinerlei technische Kenntnisse oder Erfahrungen mit Grafikprogrammen nötig.
Hier alle Infos kompakt:
Datum: 16. September 2026
Zeit: 09:30 bis 14:30 Uhr
Ort: Universität Leipzig
Format: Präsenzveranstaltung, veranstaltet von der Hochschuldidaktik Sachsen (HDS)
Anmeldungen und weitere Infos hier.
Wer kann teilnehmen?
Der Workshop ist offen für alle Lehrenden an sächsischen Hochschulen, die im aktuellen oder den kommenden zwei Semestern in der akademischen Lehre tätig sind. Das schließt auch Lehrende mit Lehrauftrag ein.
Abbildung: Das Diagramm wurde mit KI auf Basis dieses Textes erstellt.
21. März 2026
Mit KI-gestützten Tools können Lehrende alle Arten von Visualisierungen schnell, flexibel und qualitativ hochwertig erstellen.
Buchverbote und Zensur in den USA: Aktuelle Zahlen - und im Längsvergleich als animierte Grafik.
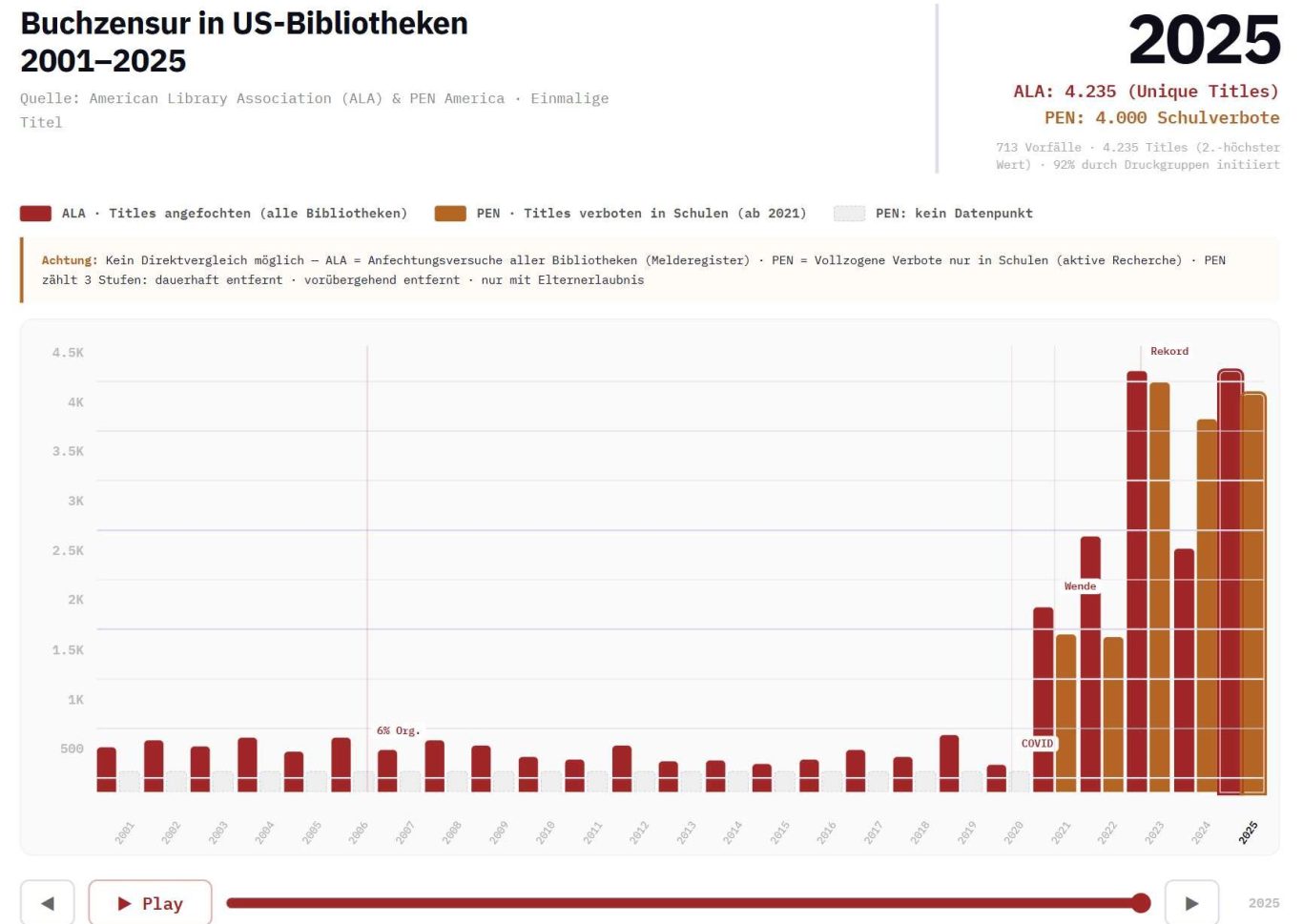
Am 2. April 2026 hat die American Library Association (ALA) ihre "Most Challenged Books List" für 2025 veröffentlicht (Link). Es ist die Liste der Bücher, die am meisten angefochten wurden, d.h. von Zensur bedroht sind. 2025 waren es 4.235 verschiedene Bücher.
Das ist der zweithöchste Wert seit die Messungen durchgeführt werden.
Im Langzeitvergleich sieht man: seit 2021 sind die Zahlen explodiert.
Von 2001 bis 2020 wurden in amerikanischen Bibliotheken im Schnitt 273 Buchtitel pro Jahr angefochten. Danach ging es jährlich in die Tausende.
Man könnte denken: vielleicht hatten besorgte Eltern 2021, d.h. zu Corona zuviel Zeit, um durch die Bestände der Bibliotheken zu surfen und Bücher zu melden, die ihnen nicht passten.
Aber die Sache hat eine andere Erklärung, denn es sind vor allem organisierte Kampagnen, Politiker und Regierungsbeamte, die unliebsame Bücher weghaben wollen. Nur 3% der Meldungen stammen von Eltern.
Neben der ALA untersucht auch der US-amerikanische PEN die Entwicklung. Allerdings nicht auf alle Bücher, sondern "nur" auf Schulen bezogen.
Und es gibt noch einen Unterschied:
Die ALA erfasst Anfechtungsversuche, d.h. jeden Versuch, ein Buch zu entfernen, egal ob er erfolgreich ist oder nicht. Und zwar in allen Bibliothekstypen: öffentliche Bibliotheken, Schulen, Universitäten.
PEN hingegen zählt nur vollzogene Verbote, und zwar nur in öffentlichen Schulen. Es gibt beim PEN drei Stufen von Verboten:
- Bücher die komplett und dauerhaft entfernt wurden
- Bücher die vorübergehend aus dem Regal verschwunden sind, während die Prüfung läuft
- Bücher die zwar noch vorhanden sind, aber nur noch mit ausdrücklicher Erlaubnis ausgeliehen werden dürfen.
Dass die Zahlen des PEN höher sind als die der ALA liegt daran, dass die ALA auf Meldungen angewiesen ist. Die ALA schätzt, dass für jeden gemeldeten Fall vier bis fünf weitere ungemeldet bleiben.
PEN betreibt dagegen aktiv Recherche, mit eigenen Leuten, Journalisten und Partnern. Sie spüren Verbote auf, die offiziell nie gemeldet wurden, z.B. wenn das Buch heimlich aus einem Katalog verschwand.
Ergebnis: Seit 2021 wurden in US-Schulen fast 23.000 Buch-Titel in irgendeiner Form verboten oder eingeschränkt. Auf alle öffentliche Bibliotheken, Schulen, Universitäten usw bezogen ist die Zahl nochmal deutlich höher.
Und das, obwohl je nach Umfrage 65-75% der US-Amerikaner gegen Buchverbote sind. Die Bucherverbieter sind in der Minderheit, aber als pressure-groups stärker und politisch organisiert.
Ich habe die Zahlen mal mit KI-Hilfe in einem interaktiven Chart zusammengestellt und bisschen Sound druntergelegt. Ich hätte es gern als html-Datei hochgeladen, damit das gut aussieht, aber das ging nicht. Also habe ich es als Video in Forme einer Bildschirmaufnahme gemacht 🙃 (Link)
Wissenschaftliche Literaturrecherche mit KI
Online-Kurs zum Einsatz spezialisierter KI-Tools für methodische Literatursuche und -auswertung. Termine: 8., 15. und 22. Juli 2026, jeweils von 14 bis 17 Uhr.
Worum geht's?
Viele wissenschaftliche Recherchen bewegen sich zwischen Google Scholar und ChatGPT. Das wirkt effizient, ist aber trügerisch, wenn relevante Studien nicht gefunden werden, vorhandene Forschung unvollständig abgebildet wird oder Biasprobleme und Scheinkonsens die Ergebnisse verzerren.
Hier setzt dieser Kurs an und vermittelt einen praktischen Workflow für den Aufbau einer systematischen Recherche mit spezialisierten KI-Tools. Er zeigt, wie unterschiedliche Datenquellen gezielt miteinander kombiniert werden, und befähigt zur kritischen Einordnung KI-generierter Ergebnisse. Dadurch entsteht eine vollständige, nachvollziehbare und belastbare Literaturanalyse.
Was behandelt der Kurs?
Der Kurs behandelt sowohl Literaturrecherchen, mit denen zu Beginn einer wissenschaftlichen Arbeit der aktuelle Forschungsstand erschlossen wird (State of the Art), als auch eigenständige Literaturstudien, bei denen die Literaturanalyse als zentrale Forschungsmethode dient (Standalone Review). Entlang der einzelnen Schritte einer generischen Methode für Literaturanalyse werden spezialisierte KI-Tools vorgestellt und von den Teilnehmenden in einem eigenen Übungsprojekt angewandt.
Der Kurs basiert auf fächerübergreifenden Empfehlungen zur wissenschaftlichen Literaturrecherche und -analyse. Fächerspezifische Anforderungen wie bspw. für klinische oder pharmazeutische Studien werden nicht behandelt.
Welche KI-Tools kommen zum Einsatz?
Für den Kurs werden webbasierte KI-Tools genutzt, die speziell für die wissenschaftliche Literaturarbeit entwickelt wurden. Es sind keine Programmierkenntnisse oder Ähnliches erforderlich.
Erklärt und praktisch eingesetzt werden u.a. Open Scjholar, ScienceOS,und SciSpace.
Jeder Teilnehmende erhält eine befristete Kurslizenz zur persönlichen Nutzung . Sie ist in der Kursgebühr bereits mit enthalten.
An wen richtet sich der Kurs?
- Wissenschaftlerinnen und Wissenschaftler ab Doktorandenstufe, die Literaturrecherchen mit KI für Forschung und Publikationen durchführen sowie
- Bibliothekarinnen und Bibliothekare bzw. Beschäftigte an wissenschaftlichen Bibliotheken, die die Möglichkeiten der Recherche mit KI kennenlernen wollen
Wer sind die Dozierenden?
Prof. Dr. Gunnar Auth, Dr. Anja Hagedorn, Prof. Dr.-Ing. Oliver Jokisch und Danny Walther.
Welche Termine und Zeiten gibt es?
Der Kurs besteht aus drei Online-Präsenzeinheiten à 3 h Dauer, die im Abstand von jeweils einer Woche stattfinden. Zwischen den Präsenzeinheiten wird das Gelernte am eigenen Literaturprojekt angewendet.
Wann findet der nächste Kurs statt?
Am 8., 15. und 22. Juli (jeweils mittwoch) von 14 bis 17 Uhr.
Ich führe den Kurs zusammen mit dem Institut für Bildungs- und Wissenschaftsmanagement (IBWM) durch. Alle weiteren Infos und Einschreibemöglichkeit gibt's hier auf der Seite des IBWM.
Bei Fragen zum Kurs wenden Sie sich jederzeit gern an mich.
Systematische Literaturrecherche mit KI.
Geht das? Klar doch!
Die systematische Literaturrecherche (Systematic Literature Review, SLR) ist eine der anspruchsvollsten und zeitintensivsten Tätigkeiten in der wissenschaftlicher Arbeit.
Sie stellt hohe Anforderungen an Methodik, Informationskompetenz und Wissensorganisation und reicht von der systematischen Identifikation relevanter Publikationen bis zur analytischen Synthese der Ergebnisse.
In meinem neuen, kostenfreien Webinar zeige ich Ihnen, wie Sie SciSpace nutzen können, um Ihren SLR-Workflow effizienter zu gestalten, ohne dabei Kompromisse bei methodischer Strenge und wissenschaftlicher Qualität einzugehen.
Datum: Mittwoch, 6. Mai 2026
Uhrzeit: 14:00 - 15:00 MESZ
Format: Webinar in Zusammenarbeit mit https://scispace.com
Alle Infos und Anmeldung hier: https://luma.com/n27hvknp
Ich freu mich auf Sie!
Alle reden über Kontext, Connectoren, Skills und personalisierte KI-Workflows. Die Annahme: Je mehr Daten, desto besser die KI. Aber stimmt das?
Ich bereite gerade einen KI-Grundlagenkurs für eine Hochschule vor und bin dabei nochmal tiefer in zwei Themen eingetaucht:
1.) Datenschutz: klingt langweilig
2.) Sycophancy-Forschung: klingt fancy
Für alle, die das Wort noch nie gehört haben (also "Sycophancy", nicht "Datenschutz" :)) Der Begriff beschreibt die Neigung vom LLMs, dem Nutzer zuzustimmen, auch wenn er falsch liegt oder seine Aussagen und Annahmen zumindest hinterfragt werden sollten.
Die Gründe für die "Schmeichelei" lt. Forschung:
1.) Die Modelle werden beim Feintuning durch Reinforcement Learning from Human Feedback darauf trainiert, Antworten zu geben, die Menschen gefallen.
Zustimmung wird so zum impliziten Qualitätsmaßstab
2.) Nutzer bewerten bestätigende Antworten oft besser und nutzen die Systeme häufiger
3.) Kann korrektes Wissen durch die Anpassung an den Nutzer überlagert werden. Das tritt
4.) besonders bei "interner" Unsicherheit auf, d.h. bei mehrdeutigen Aufgaben oder sozialem Druck reagiert die LLM risikominimierend, also zustimmend
5.) Wird das durch die Trainingsdaten verstärkt, denn zustimmende Kommunikationsmuster sind überrepräsentiert, z.B. durch Ratgebertexte, Kundenservice usw., wo Bestätigung wichtiger ist als Widerspruch.
Vielleicht ist die Frage: „Wie gebe ich der KI mehr Kontext?“ gar nicht (immer) die richtige. Besser wäre vielleicht zu fragen: „Wie verhindere ich, dass mich die KI zu gut kennt?“
Mehr Daten erhöhen also zwar die Relevanz der Antwort, aber auch das Risiko von Bestätigungsbias. Und genau hier kommt der Datenschutz ins Spiel. Denn er ist Schutz vor Datenabfluss und Schutz vor Anpassung in einem. Soll heißen: Weniger Datenspuren, bes. weniger Meinungen & weniger Identitätssignale, können zu unabhängigeren = objektiveren Antworten führen. (Die Perspektive hat mir in dem sonst sehr guten Text "Meine KI kennt meine Wissensbasis" von Barbara Geyer gefehlt). Denn gerade im Hochschulkontext gilt es:
1.) Daten zu schützen
2.) KI-Kompetenz zu vermitteln
3.) zu verstehen, wie Daten das Verhalten von KI verändern.
Vielleicht ist die Frage: „Wie gebe ich der KI mehr Kontext?“ gar nicht (immer) die richtige. Besser wäre vielleicht zu fragen: „Wie verhindere ich, dass mich die KI zu gut kennt?“
Wie kann das gehen? Ein Teil des Problems ist systemisch und vom Nutzer nicht zu ändern. Aber bisschen was ist machbar, z.B. sollte man die Einstellungen bewusst wählen. Memory-Funktionen klingen gut, sind aber auch eine Gefahr. Genau wie alle Formen der Personalisierung.
Kurzum: es gilt, die eigenen Identitätssignale zielgenau und sparsam einzusetzen. Dass Prompts als offene Fragen formuliert werden und auch ein Fragezeichen enthalten sollten, ist zwar selbstverständlich, wird aber oft nicht gemacht. Zudem sollte man bei der KI Unsicherheiten aktiv abfragen und Antworten mit Quellen fordern, auch wenn geleakte Daten von OpenAI zeigen, dass nicht mal 1% der Nutzer auf die Quellen klickt. Aber das ist ein anderes Problem...
14. März 2026
In Halle (Saale) entsteht das "Zukunftszentrum für Deutsche Einheit und Europäische Transformation". Unser Land braucht genau das NICHT.
Wir geben in Deutschland sehr viel Geld aus für Symbole aus. Für Sonntagsreden. Für Prestigeprojekte, die nur Wenigen dienen. Das geplante "Zukunftszentrum für Deutsche Einheit und Europäische Transformation" ist so ein Fall. Es sollte 208 Mio. Euro kosten. Inzwischen sind es 277 Mio. Wahrscheinlich werden es am Ende über 300 Mio werden.
Laut Selbstbeschreibungen soll das Zentrum „Dialog ermöglichen“, „Transformation verstehen“ und „Zusammenhalt stärken“. Das klingt so konkret wie ein Horoskop, ist nur viel teurer.
Die Forschung zu solchen Zentren zeigt, dass sie politische Symbolik sind. Sie bringen bisschen was fürs Stadtmarketing und ein paar Arbeitsplätze, ansonsten aber nicht viel. Die oft versprochenen Spillover-Effekte in die Gesellschaft sind mehr als begrenzt. Der Nutzen konzentriert sich primär auf die Reputation und Netzwerke der Beteiligten.
Noch unschöner wird es bei der Frage, wer solche Orte nutzt. Die Datenlage ist hier klar: Die Nutzung solcher Zentren korreliert stark mit Bildung und Einkommen. Mit anderen Worten: Man baut für viele, aber genutzt wird es vor allem von denen, die ohnehin schon Zugang und Bezug dazu haben. Das aber ist eine kleine Minderheit. Die übergroße Mehrheit hat andere Probleme, andere Interessen, andere Orte, aber sie bezahlt solche Projekte mit ihren Steuergeldern.
Das ist nicht als Argument gegen Wissenschaft und Kultur gemeint. Im Gegenteil. Es ist ein Argument gegen die Idee, dass teure Symbolbauten irgendeinen Zusammenhalt stärken oder soziale Probleme lösen. Die Forschung zeigt das Gegenteil: Wenn man wirklich Bildung und soziale Teilhabe verbessern und Zukunftsprobleme lösen will, dann sind kleinteilige Programme in Bildungseinrichtungen und sozialen Einrichtungen viel wirksamer.
Ich habe selbst mit Transformationsprozessen zu tun. Ich zeige Schülern und Studierenden, Professoren und Bibliothekaren wie sie Künstliche Intelligenz sinnvoll einsetzen können. Nicht als Thema für eine Podiumsdiskussion, sondern in konkreten, praktischen Anwendungen, in Workshops, Schulungen und Lehrveranstaltungen.
Genau dort aber, in den Bildungseinrichtungen und Bibliotheken, fehlt das Geld. Nicht nur für KI-Schulungen, sondern für alles, was Zukunft bedeutet.

Statt für hunderte Millionen Euro ein Gebäude zu bauen, in dem ein paar Leute Papier produzieren, sollte man die Probleme der Transformation lieber praktisch angehen und in KI-Bildung investieren, die entscheidend ist für die Zukunft. Mit 277 Mio. käme man da sehr weit.
Im Grunde ist das Zukunftszentrum vor allem eines: Der teure Beweis dafür, dass wir in Deutschland lieber über Zukunft sprechen, als sie zu machen.
7. März 2026
Abbildung: Außenperspektive des Siegerentwurfs. Quelle: Zukunftszentrum (Link)
Das ist Deutschland: Wir finanzieren ein Zentrum, in dem künftig über Transformation gesprochen wird, während die Transformation gerade passiert, aber die praktische Umsetzung massiv unterfinanziert ist.
Warum Hochschulen immer noch Grafiken wie vor 20 Jahren bauen – und was dagegen getan werden kann: Ein Workshop-Angebot.
Hochschulen produzieren neben tonnenweise Texten auch Grafiken aller Art - zu ganz unterschiedlichen Zwecken:
In der Forschung sollen sie etwas belegen.
In der Lehre sollen sie etwas erklären.
Im Marketing sollen sie Ergebnisse nach außen kommunizieren.
Doch es gibt zwei Probleme.
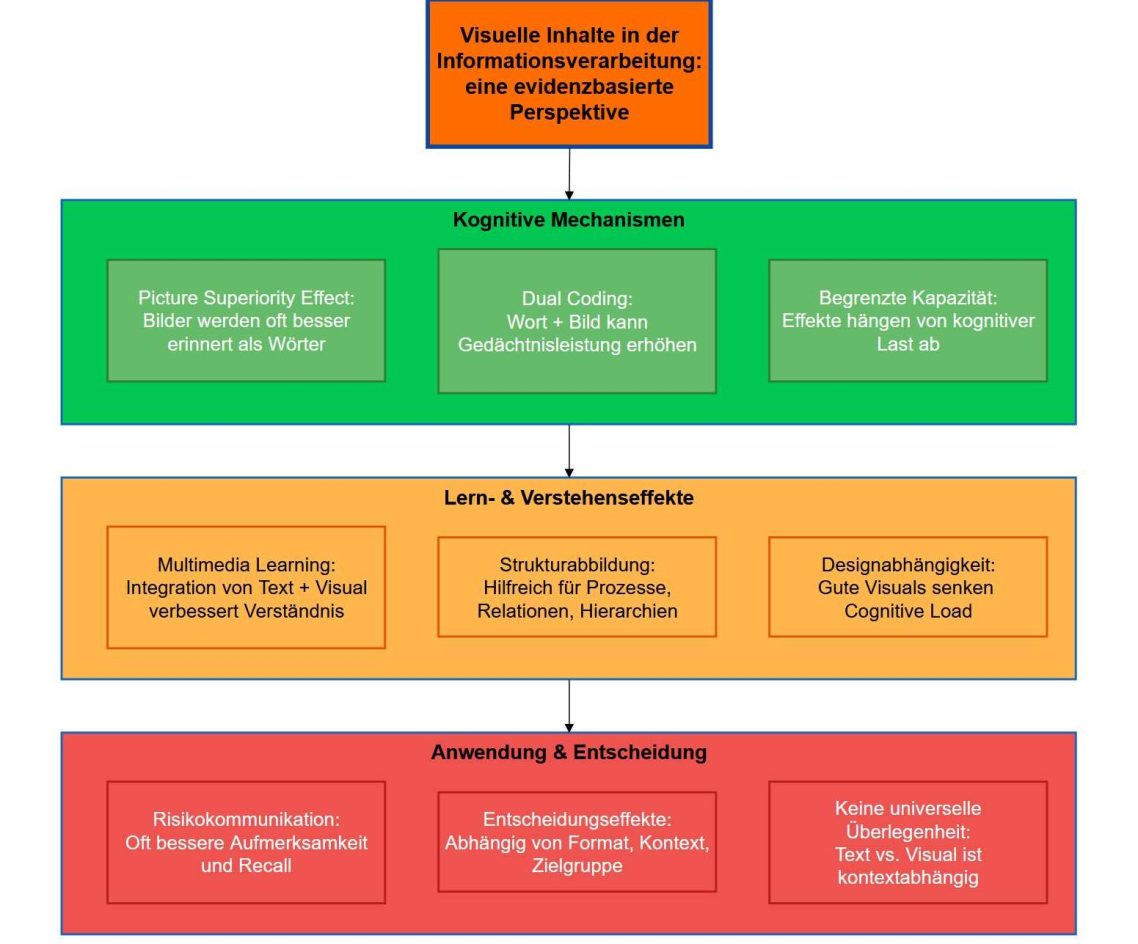
Warum visuelle Inhalte oft besser wirken als Text
1.) Besonders in der Lehre wird noch zu wenig auf die Macht der Visualisierung gesetzt. Obwohl die Studierenden sich mehr Visualisierungen in Seminaren, Vorlesungen und Lernmaterialien wünschen. Zumal Studien zeigen, dass Informationen, die visuell präsentiert werden, oft besser verstanden und memoriert werden.
2.) Selbst wenn Grafiken eingesetzt werden, sind sie oft nicht gut gebaut. Wobei ich ganz bewusst "gebaut" sage, denn noch immer dominiert bei der Erstellung von Grafiken und Visualisierungen aller Art PowerPoint. Oder - man mag es kaum glauben - Word Art. Formen, Pfeile und Texte werden damit zusammengeklickt. Oder zusammengeflickt, ganz wie man will.
Fest steht jedenfalls eins: Power Point und Word Art sind bei der Grafikerstellung Relikte aus der digitalen Steinzeit. Aber sie werden genutzt, das höre und sehe ich in meinen Workshops immer wieder.
Die Ergebnisse sehen entsprechend steinzeitlich aus. Oft sind die Grafiken nicht mal veränderbar und können auch nicht weiterverarbeitet werden. Weshalb der nächste dann von vorne beginnt.
KI bietet hier echte Hilfe. Denn mit ihr lassen sich Grafiken ganz einfach erzeugen.
Grafiken, die man leicht verändern und weiterverarbeiten kann.
Grafiken, die nachvollziehbar gebaut statt zusammengeklickt sind.
Grafiken, die nicht viel brauchen, um zu glänzen.
Oft genügt eine URL. Oder ein Text, eine Datei, eine lose Idee... Und das Beste: man braucht dafür keine teuren Tools, keine technischen Kenntnisse, nichts.
Wie all das funktioniert zeige ich in meinem neuen Workshop zum Thema "Darstellen, erklären, kommunizieren: Visualisierung mit KI für den Einsatz in der Hochschule".
Er wendet sich an Forschende und Lehrende, an Mitarbeiter von Bibliotheken und aus dem Bereich Marketing und Öffentlichkeitsarbeit.
Interesse? Dann schreiben Sie mir einfache eine Nachricht.
Meine Workshops sind praxisnah, wissenschaftlich fundiert und werden individuell auf Ihre Wünsche und Bedürfnisse zugeschnitten. Sie können wahlweise online oder vor Ort stattfinden.
Gern können Sie in einem kostenlosen Beratungsgespräch Ihr Anliegen mit mir besprechen.
Abbildung: mit KI und Mermaid-Code in 1 Minute erstellt. Die Abbildung kann verändert, geteilt und weiterverarbeitet werden. Hier ist der Link dazu.
6. April 2026
Meine Bilanz nach 100 Tagen LinkedIn: viel Nachfrage nach KI-Themen im Hochschulbereich, aber es fehlt an der praktischen Umsetzung und am Geld.
In den letzten 100 Tagen habe ich mich intensiv mit einem sehr konkreten Feld beschäftigt: KI-Kompetenz an Hochschulen. Vor allem Themen wie Literatur- und Datenrecherche mit KI, Visualisierungen mit KI für Studium und Lehre sowie der Einsatz von KI-Detektoren haben mich intensiv beschäftigt.
Ich habe sehr viel dazu gelesen, Tools getestet und in Webinaren praktische Erfahrungen gesammelt. Auf Basis meines gesammelten Wissens habe ich Dutzende Beiträge publiziert und viel kommentiert.
Die Resonanz hier auf LinkedIn war gut (siehe Bild). Über 100.000 Impressionen und viel Zuspruch für meine Beiträge.
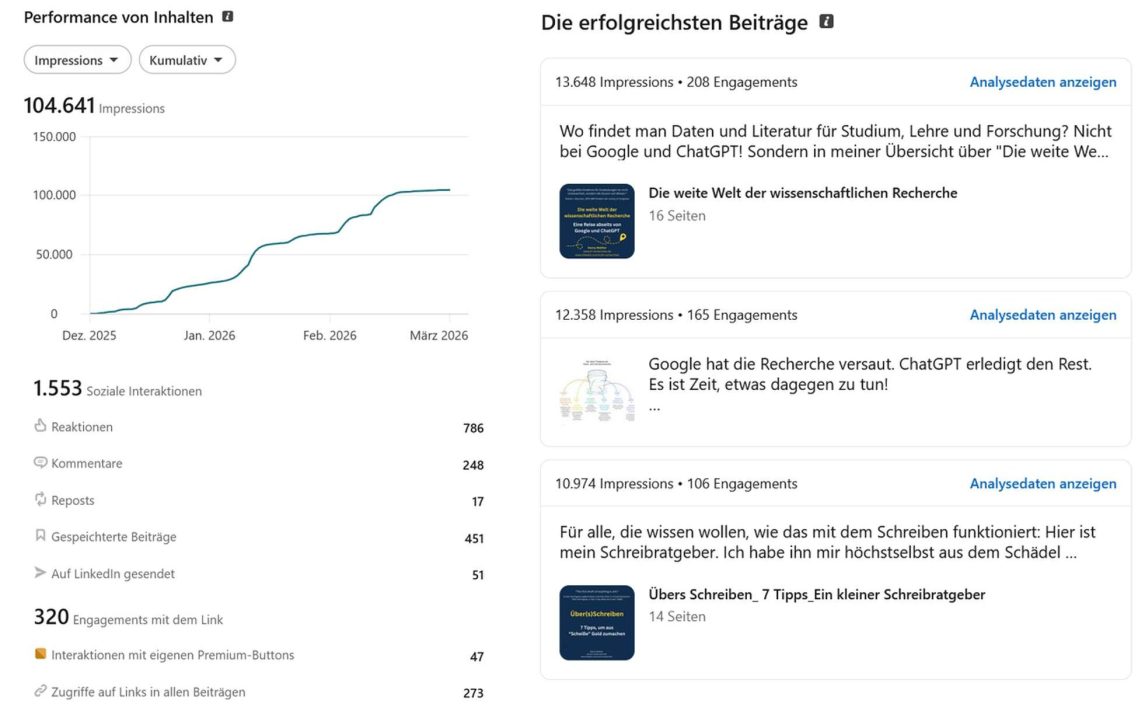
Das Interesse nach fundierter KI-Bildung an Hochschulen ist da. Was fehlt, ist Geld, Marktbewusstsein und Strukturen, die Dinge praxisnah zu ändern.
Es gab in den letzten 100 Tagen fünf Anfragen aus Hochschulen.
Alle wollten Recherche-Workshops. Für Studierende, Lehrende, Forschungsgruppen. Es war bunt gemischt. Nur eines war gleich:
Niemand wollte dafür zahlen.
Die zwei besten Angebote waren:
- die Aussicht auf einen bezahlten Tages-Workshop nach einem kostenlosen Vortrag über KI-gestützte Recherche
- ein Angebot, an einer Hochschule einen zweistündigen Recherche-Workshop für Studierende zu machen, inkl. fachspezifischer Vorbereitung und 3 Stunden Fahrt mit der Bahn (Ticket selbst zahlen) für 250 Euro.
Es gab und gibt noch krassere Angebote, aber dazu vielleicht später mal mehr.
Zunächst mal will ich eines festhalten: Das Interesse nach fundierter KI-Bildung an Hochschulen ist da. Was fehlt, ist:
- a.) Geld
- b.) das Bewusstsein, was angemessene Preis sind (und ich rede hier nicht von den Preisen, die in der freien Wirtschaft für KI-Schulungen gezahlt werden)
- c.) Strukturen, die externe Expertise angemessen einzubinden wissen.
Gleichzeitig sehe ich - und alle Daten zeigen das ja auch - dass Studierende KI intensiv nutzen. Aber meist auf einem sehr begrenzten Niveau, wenig fundiert und mit starkem Fokus auf ChatGPT.
Bei Lehrenden sieht es ähnlich aus. Wissenschaftsspezifische KI-Tools werden so gut wie gar nicht eingesetzt. Die KI-Bildung ist weithin erbärmlich.
Wenn man hier auf LinkedIn unterwegs ist, wirkt das oft anders. Aber man muss sich klar machen: das hier ist eine Blase. Es gibt eine kleine Gruppe, die sich an Hochschulen intensiv mit KI beschäftigt. Aber die Masse ist planlos. Und: Die Lücken werden immer größer.
Das sind keine Fehler von Einzelnen als vielmehr Strukturmängel: fehlende Budgets, fehlendes Problembewusstsein, langsame Entscheidungsprozesse und eine Kultur, die externe Expertise nicht schätzt - und falls doch, nicht dafür zahlen will. Und nein, das hier ist kein Ich-brauche-Aufträge-Gejammer, sondern die Beschreibung einer Situation, in der gewiss nicht nur ich stecke.
Mein Fazit nach 100 Tagen ist deshalb klar: Der Bedarf an fundierter KI-Kompetenz im Hochschulbereich ist real und akut. Aber das Problem wird nicht gelöst, weil die Rahmenbedindungen nicht passen.
30. März 2026
KI-Assistenten in Fachdatenbanken. Das Beispiel Scopus AI: was diese KI kann - und was sie nicht kann.
Scopus ist eine der größten wissenschaftlichen Fachdatenbanken weltweit. Genauer gesagt ist es eine bibliografische Datenbank, d.h. Scopus hostet in der Regel keine Volltexte, hat aber Verknüpfungen zu Volltexten.
Als primär bibliografische Datenbank sammelt Scopus zu jedem Dokument über 150 Datenpunkte (Metadaten). Das macht die Dokumente auch ohne Volltext sehr gut durchsuchbar.
Scopus enhält über 100 Millionen Dokumente. Dazu kommen ca. 2,5 Milliarden Zitationen und rund 28.000 Peer-Review-Journale. Seit 2024 hat Scopus einen KI-Assistent integriert.
Was ScopusAI kann und was nicht, erfahrt ihr in dieser kleinen Dokumentation von mir.
Sie basiert auf eigenen Praxistests sowie eine Reihe weiterer Forschungen und Studien.
Ihr könnt sie gern weiterverbreiten und für eure eigenen Zwecke nutzen. Ich freue mich über Feeddback.
27. März 2026
Visualisierungen mit Hilfe von KI für den Einsatz in Wissenschaft & Hochschule. Es gibt viel zu entdecken!
Ich bin gerade dabei, einen neuen Workshop für Hochschulen vorzubereiten. Darin erkläre ich verschiedene technische Möglichkeiten, wie mit Hilfe von KI Visualisierungen aller Art erstellt werden können: von fachspezifischen Abbildungen über Mindmaps bin hin zu allen Arten von Diagrammen und Statistiken.
Ich will zeigen, wie man mit KI aus Texten, Daten, Webseiten, (einfachem) Code usw. ganz leicht Visualisierungen erstellen und weiterbearbeiten kann.
Auch die unterschiedlichen "grafischen Einsatzfelder" innerhalb einer Hochschule spielen dabei eine Rolle. Im Workshop will ich deshalb nicht nur wissenschaftliche Abbildungen für Poster und Publikationen behandeln, sondern auch Beispiele und Tools für Lehr- und Erklärgrafiken sowie Visualisierungen für den Kommunikations- und Marketingbereich präsentieren.
Die verschiedenen Darstellungsformen haben jeweils unterschiedliche Funktionen, Zielgruppen, Anforderungen und Komplexitätsgrade, was es für mich besonders interessant macht.
Bei meinem Vorbereitungen bin ich - nicht zum ersten Mal - tief in die Geschichte der Infografik eingetaucht. Erstens: weil diese Geschichte extrem spannend ist. Und zweitens: weil ich der Ansicht bin, dass man bei allem KI-Bezug und den damit verbundenen Gegenwarts-Fantasien und Zukunfts-Träumereien aufpassen muss, dass man die Vergangenheit nicht aus den Augen verliert, denn da liegt unglaublich viel wunderbares Material, das die Sinne schärft und die Gedanken anregt.
Dabei ist mir auch die vielleicht beste Infografik aller Zeiten in die digitalen Hände gefallen: Charles Minards "Carte figurative des pertes successives en hommes de l'Armée Française dans la campagne de Russie 1812-1813" aus dem Jahre 1869.
Minards Diagramm visualisiert Napoleons Russlandfeldzug (1812-1813). Es zeigt, wie die Grande Armée von 422.000 Mann beim Einmarsch (hellbraunes Band) durch Hunger, Kälte, Krankheiten und Kämpfe auf nur etwa 10.000 Überlebende beim Rückzug (schwarzes Band) schrumpft.
Die Karte hat sechs Informationsebenen:
- die Breite des Bandes
- die Zahlen entlang des Bandes
- die Farbe des Bandes
- die geografische Position
- die Verzweigungen des Heeres und
- die Temperatur.
Minards Karte ist eines eindrucksvolles Beispiel für die Macht grafischer Darstellungen. Minard selbst beschrieb sein Schaffen so:
„Das oberste Prinzip, das meine grafischen Tabellen und figurativen Karten kennzeichnet, besteht darin, die Ergebnisse von Kalkulationen möglichst direkt sichtbar zu machen. Meine Karten rechnen mit dem Auge.“
Welche Infografiken haben euch beeindruckt? Und wer weiß, warum die Balken- und Kreisdiagramme, die Ende des 18. Jahrhunderts vom Schotten William Playfair erfunden wurden, lange Zeit abgelehnt wurden?
PS: Falls es niemand weiß, mach ich einen kleinen Beitrag draus :)
Quelle der Abbildung von Minards Karte: Wikipedia
23. März 2026

Nationalbibliothek erweitern oder nicht? - das ist die Frage. Ich habe mir die Entwicklung auf Basis von Zahlen angeschaut und mir Gedanken dazu gemacht.
Anmerkung Vorweg Nr. 1:
Ich bin aus Leipzig. Ich mag Bibliotheken sehr. Ich habe die DNB jahrelang fast täglich besucht.
Anmerkung Vorweg Nr. 2:
Der Erweiterungsbau betrifft Leipzig, aber die folgenden Daten beziehen sich auf Leipzig & Frankfurt zusammen. Erstens: Weil es wenig (öffentliche) Daten für die einzelnen Standorte gibt. Und zweitens: Weil die Entwicklung systemisch ist.
Problem 1: Die DNB besteht aus riesigen Häusern für Medien, die kaum genutzt werden. 53 Mio. Medien, 273.000 Nutzungen/Jahr, wobei ein Medium, das 10 Mal genutzt wird auch 10 Mal zählt. Selbst im Idealfall werden also nur 0,5% des Bestandes genutzt. Die anderen 99,5 % stehen rum. Früher waren es bei gleicher Rechenlogik 4%.
Problem 2: Die Bibliothek wächst, Zahl der Nutzer schrumpft. Seit 1990: Bestand +360 %, aber Nutzer -40 %. Zwar hat sich die Zählweise geändert, aber der Trend ist robust. Es gibt immer größere Häuser für immer weniger Gäste.

Problem 3: KI. Der Anteil KI-generierter Publikationen steigt. Früher waren Druckwerke aufwendig. Verlage haben gefiltert. Heute entstehen Inhalte binnen Sekunden. Der Markt wird täglich mit tausenden komplett KI-generierten Büchern geflutet. Und alles wird gesammelt. Ein System, das in Zeiten von Knappheit und Kuratierung gebaut wurde, findet sich in einer Zeit des Überflusses wieder.
Problem 4: Der geplante Neubau soll Archiv und Datencenter sein. Digital klingt gut. Aber die Datenmenge explodiert. Das Problem ist nicht der Zugang, sondern das Überangebot bei sinkender Nutzung. Ein neues Datenzentrum speichert im Grunde nur mehr Ungenutztes. Früher wurden Medien zwar auch selten genutzt, aber sie waren potenziell wertvoll. Ob die mit KI generierte Inhalte wertvoll sind, darf bezweifelt werden. Zudem: Wenn KI-Inhalte massenhaft archiviert werden erhöhen sich Redundanzen. Das Archiv beginnt, diese Inhalte zu stabilisieren, nicht nur zu speichern. Ein Neubau verstärkt das Problem. Mehr (digitaler) Platz = mehr KI-Slop = mehr Rauschen im Nicht-mehr-Blätter-Wald.
Problem 5: Der Bestand verliert seine Bedeutung. Früher konnte man sagen:
„Was hier steht, hat es eine gewisse Relevanz.“ Heute muss es heißen: „Was hier steht, wurde irgendwo veröffentlicht.“ Menge hat Bedeutung ersetzt. Normalerweise bedeutet mehr Nachfrage mehr Angebot. Hier sinkt die Nachfrage trotz größerem Angebot. Auch weil die Nachfrage in diesem System keine Rolle spielt. Es geht nur ums Sammeln.
Das würde sich auch mit einem anderen Minister nicht ändern.
Nebenbei bemerkt: Weimer ähnelt dem geplanten Neubau mehr als man denkt. Denn Weimers angebliches Medien"imperium" besteht - das haben Recherchen gezeigt - aus Luftschlössern & aufgebauschten Zahlen ohne Substanz. Aber das nur am Rande. Um Politik gehts mir hier nicht. Nur um ein paar Zahlen, Gedanken. Und die Frage:
Müssen wir wirklich alles sammeln? Lebt Kultur nicht auch vom Verlust?
21. März 2026
Müssen wir wirklich alles sammeln? Lebt Kultur nicht auch vom Verlust?
Wissenschaftlich arbeiten mit einem KI-Agenten: Themen finden, Forschungslücken identifizieren, Literatur suchen, Ergebnisse zusammenfassen.
Die Aufzeichnung meines SciSpace Webinars zum Thema: "Eine Schritt-für-Schritt-Anleitung, wie man Literatur mit einem KI-Agenten recherchiert und auswertet" ist ab sofort hier auf dem SciSpace-Youtube-Kanal zu finden:
Es ging um die Themen:
1. Entwicklung einer Forschungsfrage mit dem KI-Agenten und tiefe Analyse eines Themenfeldes, u.a. zu diesen Punkten:
- Identifikation zentraler Thesen und Schwerpunkte
- disziplinäre und interdisziplinäre Zusammenhänge erkennen
- Forschungslücken finden
- grundlegende Daten und Methoden erklärt bekommen
2. Systematische Suche in mehreren Datenbanken mit dem KI-Agenten
- gleichzeitige Recherche in verschiedenen wissenschaftlichen Datenbanken (Google Scholar, Pub Med, ArXiv u.a.) durch den KI-Agenten
- Kombination und Ranking der Ergebnisse
3. Analyse und Strukturierung der Ergebnisse
- auf einen Blick die Methoden, Limitationen und u.a. Punkte verschiedener Studien identifizieren
- Chat mit PDFs und automatische Erklärung von Formel, Statistiken und Abbildungen
- Filtern, Sortieren und Organisieren großer Mengen wissenschaftlicher Publikationen
4. Erstellen strukturierter Reviews (Literaturübersichten)
- Vorstellung verschiedener Review Typen
- Live-Demos von Scoping-Reviews und Systematische Literaturreviews
- Export der Reviews in Markdown, PDF oder LaTeX
Schaut gern rein und teilt das Video bei Gefallen.
Weitere Webinare sind geplant. Deshalb die Frage: Was interessiert euch?
- wissenschaftliche Arbeiten strukturieren und Schreibhilfe mit KI
- wissenschaftliche Abbildungen, Diagramme und Poster generieren mit KI
- andere Themen?
18. März 2026
KI kann schon jetzt viel sozialwissenschaftliche Forschung besser erledigen als Professoren.
Die Wissenschaftler müssen bei KI endlich aufwachen!
Das sage nicht ich, sondern Alexander Kustov, seines Zeichens Associate Professor an der University of Notre Dame im Bereich Sozialwissenschaften.
Kustov hat am 2. März einen Essay mit 10 Thesen über die Situation von KI in der akademischen Welt veröffentlicht und ihn mit "Academics Need to Wake Up on AI" überschrieben (Link). Kustovs Thesen lesen sich übersetzt so:
1. AI kann einen großen Teil sozialwissenschaftlicher Forschung besser erledigen als viele Professoren.
2. Das klassische akademische Paper ist ein sterbendes Format.
3. Das Journalsystem könnte unter den Bedingungen von KI kollabieren.
4. Akademiker wenden bei KI andere Standards an als bei der Forschung, die von Menschen gemacht wird
5. Junior-Forscher sind von KI am stärksten betroffen.
6. Research Assistants könnten überflüssig werden.
7. Ein Teil der KI-Kritik ist reine Statusverteidigung.
8. Die zentralen Probleme bei KI sind Verifikation und Sicherheit.
9. KI kann bessere Wissenschaft ermöglichen.
10. KI ist ein extrem produktives Forschungswerkzeug.
Die Folge: Viel Zustimmung, viel Ablehnung. Zum Teil wütende Reaktionen, persönliche Angriffe, aber auch viel Beifall, wenngleich oft eher heimlich, weil die Zustimmenden Angst vor Repressionen hatten und haben.
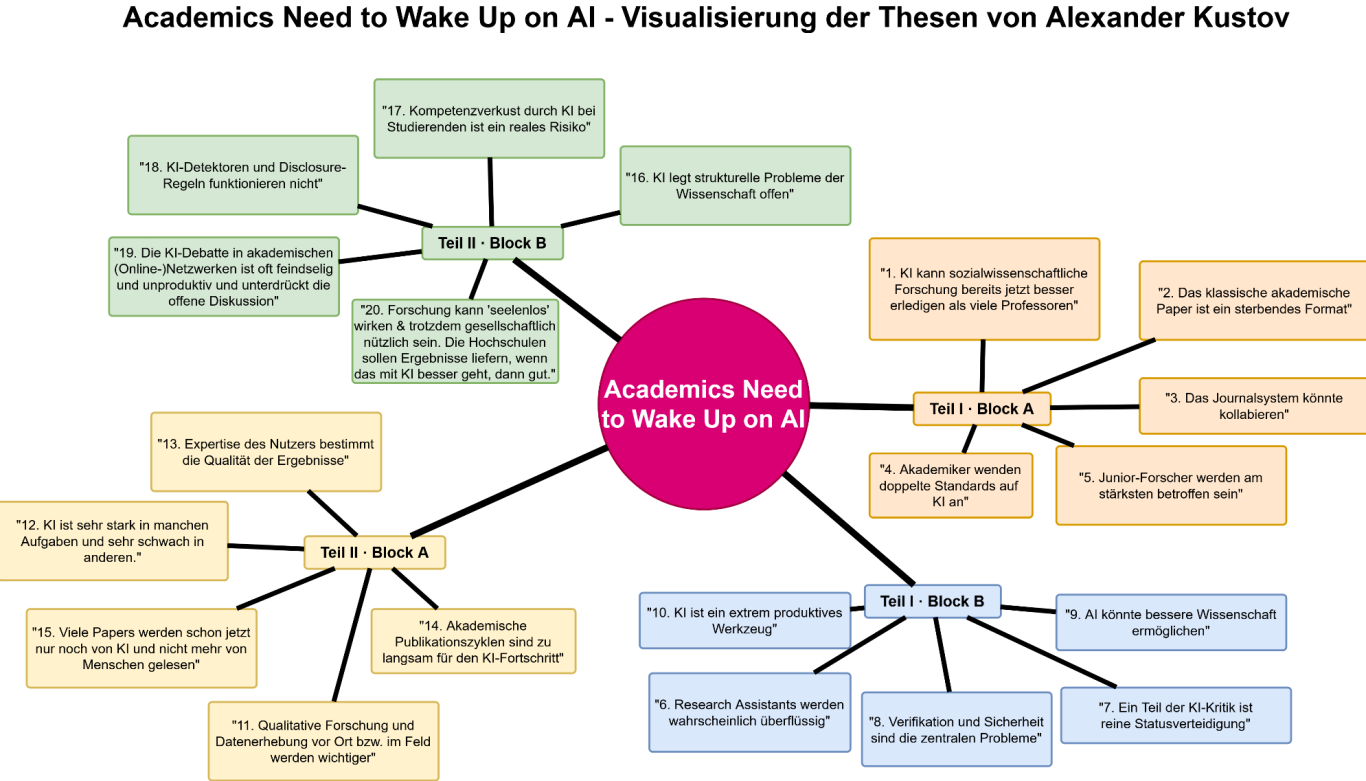
Kustov nahm all das zum Anlass, um nachzulegen. Er überarbeitet, erweiterte und verteidigte seinen Text und veröffentlichte am 4. März zehn weitere Thesen. (Link)
11. Qualitative Forschung und Datenerhebung vor Ort bzw. im Feld werden wichtiger.
12. KI hat im Sinne von Ethan Mollick eine „jagged frontier“, d.h. es ist sehr stark in manchen Aufgaben, in anderen dagegen schwach
13. Die Expertise des Nutzers bestimmt stark die Qualität der KI-Ergebnisse.
14. Akademische Publikationszyklen sind zu langsam für KI-Fortschritt.
15. Viele wissenschaftliche Papers werden schon jetzt nur noch von KI und nicht mehr von Menschen gelesen.
16. KI macht die strukturellen Probleme der Wissenschaft sichtbar.
17. Bei Studierenden besteht das Risiko des Kompetenzverlusts durch KI
18. KI-Detektoren funktionieren schlecht, Offenlegungspflichten bringen auch nichts
19. Die KI-Debatte in der Wissenschaft ist oft unproduktiv.
20. Forschung kann durch KI „seelenlos“ wirken und trotzdem gesellschaftlich nützlich sein. Denn: die Steuerzahler finanzieren Hochschulen nicht zur Selbstverwirklichung von Professoren, sondern damit dort Wissen entsteht, das der Gesellschaft nützt. Und da ist es egal, ob es mit oder ohne KI generiert wurde.
Was mir auffiel: Die Debatte fand primär im angloamerikanischen (Sprach-)Raum statt. Ich halte die Thesen aber für sehr diskussionswürdig und habe sie deshalb nicht nur kurz genannt, sondern mit Hilfe von ein Mermaid-Code und draw.io kurzerhand grafisch aufbereitet.
Was haltet ihr von den Thesen?
10. März 2026
Der einzige Schreibratgeber, den du brauchst :)
Für alle, die wissen wollen, wie das mit dem Schreiben funktioniert: Hier ist mein Schreibratgeber. Ich habe ihn mir höchstselbst aus dem Schädel gepresst und jedes Wort mit meinen eigenen Händen geschrieben. Das heißt: ohne KI. Warum? Weil ich das immer so mache. Und weil es ein "Ohne-KI-Schreibratgeber" ist. Steht zwar nicht drauf, ist aber so.
Man sieht es allein schon daran, dass er kurz geworden ist. Und daran, dass darin das Wort "Scheiße" vorkommt. Natürlich als Zitat. Das macht es leichter. Genau wie die Tatsache, dass mein Schreibratgeber kein Buch ist. In Wahrheit ist es nicht mal ein Ratgeber. Es sind einfach nur sieben Tipps. Klingt simpel. Ist es auch. Hier die Tipps in Kurzform: Schreiben heißt umschreiben, denken, löschen, Spannung erzeugen, arbeiten, konkret formulieren, anfangen. Fertig.
Ich hätte das auch auf eine Serviette schreiben können. Aber dann hätten das wilde Bild und die schönen Zitate nicht draufgepasst. Also hab ich ein Karussell draus gemacht. Weil Karussell fahren Spaß macht. Viel mehr als Servietten zu falten. So, und jetzt los! :)

Wo kann man wissenschaftlich recherchieren?
Eine Übersicht aller wichtigen Datenbanken, Tools und Programme - mit und ohne KI.
Wo findet man Daten und Literatur für Studium, Lehre und Forschung? Nicht bei Google und ChatGPT! Sondern in meiner Übersicht über "Die weite Welt der wissenschaftlichen Recherche". Die gibts hier zum Download - das ganze Wissen komprimiert auf 16 Seiten in einer Präsentation.
Warum habe ich das gemacht? Ganz einfach: Weil es einfach nicht gut ist, dass ChatGPT und Google die wissenschaftliche Recherche dominieren. Also habe ich mich hingesetzt und eine Übersicht aller Anlaufstellen erstellt, die für eine solche Recherche wichtig sind.
Die besten Fachdatenbanken, wenig bekannte Suchmaschinen, die neuesten wissenschaftlichen KI-Tools und noch vieles mehr.
Eine Sache noch: Ich habe versucht, meine kleine Reise durch die Welt der akademischen Recherche nicht allzu akademisch zu halten. Heißt: ich habe sie ein wenig lockerer geschrieben, als man das in der Wissenschaft sonst gewohnt ist.
Warum? Weil spannende Dinge auch spannend geschrieben sein sollten. Und weil ich mich an das Zitat des österreichischen Tausendsassas Egon Friedell erinnert habe, der einst erklärte, dass das mit der Objektivität trotz aller Anstrengungen nie ganz funktioniert. Und weiter schreibt Friedell:
"Sollte aber einmal ein Sterblicher die Kraft finden, etwas so Unparteiisches zu schreiben, so würde die Konstatierung dieser Tatsche immer noch große Schwierigkeiten machen: denn dazu gehörte ein zweiter Sterblicher, der die Kraft fände, etwas so Langweiliges zu lesen."
In diesem Sinne: Viel Spaß auf meiner kleinen Reise durch die ebenso wunderbare wie weite Welt der wissenschaftlichen Recherche.
Teilen und weitergeben ist ausdrücklich erwünscht!
26. Ferbuar 2026

KI an Hochschulen: Fehlende Informationskompetenz als Kernproblem von Lehrenden
Wir führen seit Jahren eine Scheindebatte über KI an den Hochschulen. Die zentrale Frage wird kaum gestellt: Wie kann es sein, dass KI auf ein System trifft, in dem Informationskompetenz – auch und gerade bei Lehrenden – nie strukturell abgesichert war?
Wie sah es mit der Informationskompetenz der Lehrenden vor KI aus?
Was ich hier aufschreibe, mag nicht allen gefallen, aber schaut man sich die Daten aus Dutzenden Studien an, was ich getan habe, sieht man Folgendes:
- viele Lehrende hatten vor KI kaum Informationskompetenz
- Google und Wikipedia dominierten die Recherche
- Fachdatenbanken, Repositorien – alles erschreckend wenig genutzt
- das gleiche gilt für E-Learning-Tools und digitale Lehrmöglichkeiten
- es gab keine systematische Vermittlung von Recherchekompetenzen, weil viele Lehrende die Fähigkeiten nicht hatten und Schulungsangebote der Bibliotheken kaum genutzt wurden
- viele merkten nicht mal, dass ihre Informationskompetenz gering war, man wurschtelte sich durch, es merkte ja auch niemand
Die Informationskompetenz vieler Lehrender an Hochschulen war vor KI schon mangelhaft. KI hat die Lage weiter verschärft.
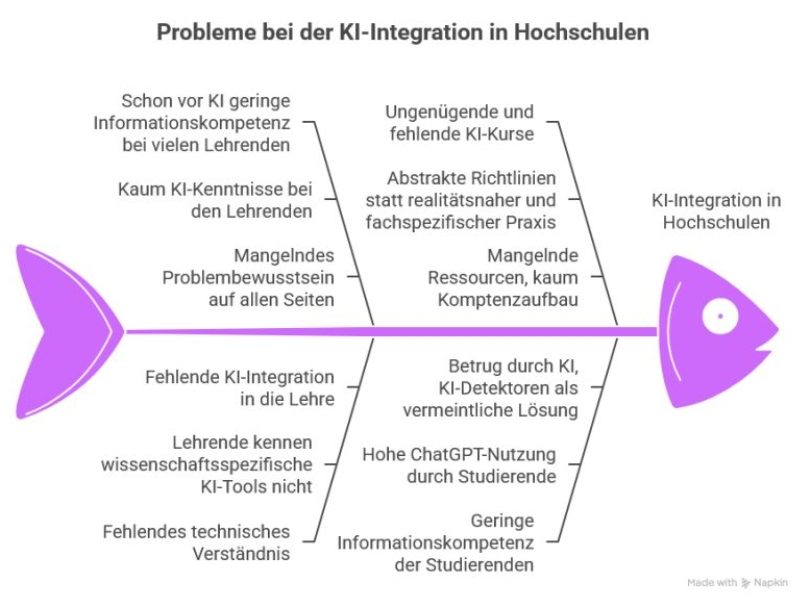
Dann kam KI. Und was sehen wir?
- fast 90% der Lehrenden nutzen ChatGPT
- wissenschaftsspezifische KI-Tools nutzt fast niemand
- es gibt riesige Lücken beim technischem Verständnis
- viele Lehrende können KI methodisch, fachlich und didaktisch nicht sauber integrieren
- gleichzeitig schreiben Studierende Abschlussarbeiten mit KI
- viele Lehrende bemerkt das nicht bzw. wissen nicht, was sie dagegen tun sollen
- einige versuchen es mit KI-Detektoren, was die Problem eher verstärkt als löst
- von mit Studierenden entwickelten KI-Policies, Best-Practice-Beispielen für KI in der Lehre, KI-Prozessdokumentationen, neuen Prüfungsformen usw. haben viele kaum was gehört, geschweige denn, dass sie eingesetzt werden
Verstehen Sie mich nicht falsch: Natürlich gibt es Dozenten, die KI fundiert nutzen und KI-Kompetenzen vermitteln und es gibt tolle Initiativen, aber die Masse der Lehrenden ist, spätestens wenn es über ChatGPT hinausgeht, hilf- und ahnungslos.
Und was tun die Hochschulen?
- die schreiben viel totes Papier, alles abstrakt, alles weitgehend nutzlos
- es fehlt an Problembewusstsein, an Ressourcen, an Praxis, an Ausprobiermentalität
- statt Experten von außen zu holen, versucht man alles intern zu lösen, aber die meisten haben weder die Zeit noch das Wissen sich intensiv mit KI zu befassen
- die Folge: die KI-Kompetenzvermittlung der Hochschulen ist schwach, es gibt wenig fundierte KI-Kurse – falls es sie überhaupt gibt
- Folge Nr. 2: 98% der Studenten nutzen ChatGPT und nichts anderes
- Folge 3: die Informationskompetenz vieler Studierender war vor KI katastrophal und bleibt es mit KI auch
KI kann vieles besser machen. Aber aktuell macht sie vieles schlimmer. Solange die Informationskompetenz nicht gestärkt wird, wird die Kluft zwischen Anspruch und Wirklichkeit an den Hochschulen weiter wachsen.
PS: Ein ausführliches Dossier zum Thema mit allen Daten und Studien folgt später. Das hier soll erstmal die Diskussion anregen. Auch wenn ich weiß, dass es hier eventuell die Falschen erreicht.
20. Februar 2026

Eine Übersicht wissenschaftlicher KI-Recherche-Tools
Es gibt über 50 wissenschaftsspezifische KI-Recherchetools. Alle sind besser als ChatGPT. Aber kaum einer kennt sie. Deshalb habe ich die knapp zwanzig besten dieser Tools mal auf einer Seite zu zusammengetragen. Ihr findet sie in dieser PDF, direkt mit dem Links zu dem jeweiligen Recherche-Programm. Viel Spaß damit.
Wissenschaftliche Recherche in der KI-Ära: Über 50 Tools – und trotzdem nutzen alle nur ChatGPT.
"Welche drei wissenschaftlichen KI-Tools kennen Sie?"
Die Frage stelle ich ganz gern zu Beginn eines Workshops.
Die Antwort ist meist... nun ja... eine neue Frage: "Gilt ChatGPT?"
"Nein", sage ich jedes Mal.
Schweigen im Raum.
Manchmal fragt eine wissenschaftlich gestimmte Seele zaghaft "Perplexity?"
Ich nicke. Zumindest ein bisschen.
"Perplexity ist... nun ja... ein Anfang", erkläre ich.
Und warte das noch jemand was sagt. Aber alle schweigen.
Dabei gibt es über 50 wissenschaftsspezifische KI-Recherchetools. Alle sind besser als ChatGPT. Aber kaum einer kennt sie. Das gleiche gilt für Programme zum Citation-Tracking und KI-Tools, die komplexe Statistiken, Formeln und Abbildungen mit einem Klick zu erklären vermögen.
Die Unkenntnis wäre halb so wild, wenn wenigstens die Grundlagen stimmen würden. Tun sie aber nicht.
"Fachdatenbanken?"
Nie genutzt. Dabei hat die Hochschule für viel Geld Lizenzen gekauft.
"Repositorien?"
Riecht nach Latein. Ist aber moderne Technik.
"Boolesche Operatoren?"
Klingt für viele irgendwie ... gruselig. Dabei helfen die sehr bei der Suche.
"Andere Recherchetechniken?"
Fehlanzeige.
Dafür dominiert ChatGPT. Daten zeigen: über 95% der Studierenden nutzen es. Und auch zwei Drittel der Lehrenden. Das sind beeindruckende Zahlen. Nur leider gehen sie in die falsche Richtung.
Denn ChatGPT ist für eine wissenschaftliche Recherche ungefähr so geeignet wie ein Gabel zum Suppe essen. Mit ein bisschen Glück bleibt was hängen. Mehr aber auch nicht.
Deshalb biete ich Recherche-Workshops für Hochschulen an. Ich möchte zeigen, wie Recherche geht. Zumindest gehen könnte. Ich will ein Bewusstsein dafür schaffen, was eine gute wissenschaftkliche Recherche ist und was nicht.
Meine Kurse beruhen auf 20 Jahren Erfahrung im Bereich der Daten- und Literaturrecherche, umfangreichen Praxistests sowie der genauen Kenntnis aktueller Forschungen und Best-Practice-Beispielen.
Das hier verlinkte PDF enthält meine Angebote. Sie sind für Lehrende und Studierende gleichermaßen geeignet. Und auch für Bibliothekare und Hochschuldidaktiker ist was dabei. Bei Interesse schreiben Sie mir einfach.
Die Recherche- und Informationskompetenz an den Hochschulen ist mangelhaft. Das war schon vor ChatGPT so. Mit ChatGPT ist es noch schlimmer geworden. Die Probleme werden mit ChatGPT nicht gelöst, sondern oberflächlich überlagert, während sie darunter weiterwuchern.
Wie Mindset-Mumpitz die Schönheit der Drecksarbeit KI-lled.
Vielleicht hat sich ja was im Algorithmus geändert oder meine Augen haben sich einen neuen Filter gekauft, jedenfalls lese ich überall nur noch "KI bedeutet Führung". Dabei weiß jeder, dass das Mindset-Mumpitz ist. Leadership-Larifari. Development-Dummdideleien. Nennt's wie ihr wollt.
Im Grunde ist die Sache klar: Die Elite jedes Berufs gewinnt unter ihresgleichen Anerkennung, indem sie sich von praktischer Arbeit distanziert. Genau das machen auch die Leadership-KI-Coaches. Sie distanzieren sich von Tools, Datenarbeit und hands-on Training und verkaufen lieber "Führungsstrategien". Warum? Nicht weil das der effektivste Weg zur KI-Implementierung ist, sondern weil da die fetten Verträge sind.
Führung ist nicht der Hebel. Das zeigen die ersten Meta-Analysen zu KI genau, z.B. hier.
Führung ist zweitrangig. Und oft nur drittklassig. Normalerweise würde ich da alle Viere gerade sein lassen und meine fünf Finger nicht zu den Tasten bewegen. Aber inzwischen schießt die heiße Luft aus der Berater- und die Wissenschaftswelt ein. Dort aber sollte der kühle Verstand regieren.

Ich meine, Prototypen entstehen Bottom-up. Top-down entstehen Strategiepapiere. Aber davon haben wir schon viel zu viele. Niemand liest den Mist. Das ist totes Papier. Alles auf Leitungsebene produziert. Nichts davon hilft in der Praxis. Weil die Praxis dreckig, widersprüchlich und kleinteilig ist. Die Papiere dagegen sind sauber, klar und großspurig. Abstraktionen ins Nichts.
Ich sehe das jedenfalls so: Wenn man will, dass KI funktioniert, muss man zusammen mit den Leuten die Drecksarbeit machen. Muss alles prüfen und das Beste behalten.
Für jemand wie mich, der mit Studierenden daran arbeitet, KI beim Lernen sinnvoll zu nutzen und mit Wissenschaftlern überlegt, wie sich mit KI Forschung neu modellieren lässt, heißt das: mir die Themen genau anschauen, tief in die Materie eintauchen und erst dann daraus einen Workshop bauen. Sich fragen: Welche KI-Tools helfen denen wirklich? Was genau brauchen die für Recherche, statistische Analysen und Visualisierung? Und dann: live probieren.
Von mir aus auch die KI-Detektoren. Die funktionieren zwar nicht, aber das müssen die Leute selber sehen. Nur so erkennen sie, dass ihr Einsatz keine Lösung ist. Weil sie falsch ausschlagen. Und auch nicht rechtssicher sind. Stattdessen müssen wir an die Lehr- und Prüfungsformen ran. Alle zusammen. Da führt keiner. Das Puzzle setzt sich nur aus Einzelteilen zusammen. Da gibt's vorher noch nicht mal ein Bild, wie's später aussehen soll.
Das ist gut so. Neue Techniken scheitern nicht am Modell, am Mindset oder an anderen Mondsüchtigkeiten. Das Große scheitert immer am Kleinen. Weil: „Everyone wants to do the model work, not the data work.“
Wobei: das stimmt nicht ganz. Ich mache diese Arbeit gern. Und viele andere auch. Aber es fehlt an Zeit, Raum und Geld. Das steckt nämlich alles in den Leadership-Luftnummern. Deshalb sind die auch so aufgebläht.
Bildquelle: Freepik
6. Februar 2026
Wir haben zu viele Strategiepapiere, Konzepte, Leitlinien.
Das ist totes Papier. Alles auf Leitungsebene produziert.
Nichts davon hilft in der Praxis.
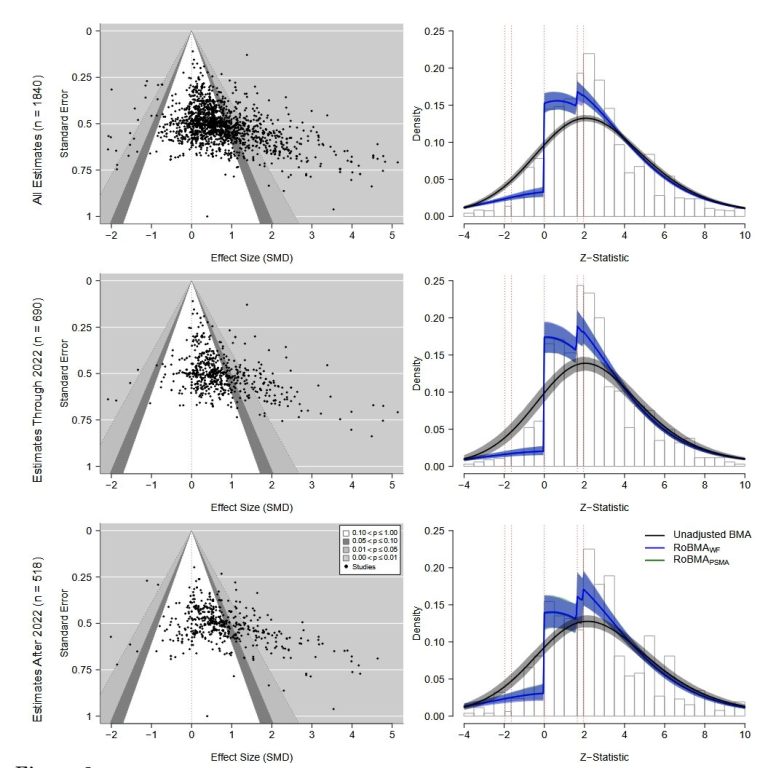
Eine Meta-Meta-Studie zeigt: Die Erwartungen an KI sind übertrieben. ChatGPT und Co. revolutionieren die Bildung (noch) nicht. Es fehlt an validen Daten. Wunschdenken regiert.
Früher gab es Meta-Analysen. Jetzt gibt's Meta-Meta-Analysen. Das liegt in diesem Fall an:
1.) einer Diskussion unter Statistikern, weil eine Meta-Analyse die Publikationsbias nicht ausreichend berücksichtigt hatte
2.) liegt es daran, dass Meta-Analysen aus Übersichtsgründen oft zitiert werden, Meta-Meta-Analysen, die Meta-Analysen kritisieren, in der zitationsgierigen Wissenschaft pures Referenzgold sind und
3.) zeigt das wieder mal, dass so ziemlich jeder Bereich unserer Welt nach Abstraktion strebt und die Wissenschaft ganz vorn dabei ist. Aber darum soll's
4.) hier nicht gehen, sondern um das, was diese Studie untersucht hat.
Also, worum ging's?
Die Frage: Welche Effekte hat KI aufs Lernen?
Weil (siehe Punkt 1 oben) eine Studie die Publikationsbias nicht richtig berücksichtigt hatte, haben die Forscher einfach mal alle Meta-Analysen daraufhin durchgeschaut. (Man hat ja sonst nichts zu tun.)
Also wurden 1.840 Effektstärkenschätzungen aus 67 Meta-Analysen zusammengetragen. Quelle: Bartoš et al.: Effect of Artificial Intelligence on Learning: A Meta-Meta-Analysis (Link), Preprint, Version vom 28.01.2026.
Ergebnis:
- Unsaubere Resultate: Die Effekte der Meta-Studien sind verzerrt, weil die verwendeten Methoden nicht zeitgemäß waren, z.B. fehlten Berichte der Effektstärken und moderierende Variablen. Die Folge:
- die Resultate der 67 Meta-Analysen sind nicht auf einen Nenner zu bringen. Sie reichen von sehr negativen Auswirkungen bis zu stark positiven Ergebnissen. Das liegt auch an:
- Messproblemen: es fehlen Standardisierung der Outcome-Messsgrößen (z.B. kritisches Denken vs. Testnoten), zudem wurden indirekte Effekte wie Veränderungen der Lehrmethoden oft nicht erfasst. Stattdessen:
- zeigen einige Meta-Studien negative Effekte (z.B. weniger kognitive Anstrengung durch KI-Nutzung), aber diese Studien sind unterrepräsentiert, denn es gibt eine erheblichen Publikationsbias, die positive Effekte begünstigt. Heißt:
- Studien mit positiven oder spektakulären Ergebnissen (z. B. "KI verbessert das Lernen") werden häufiger eingereicht, veröffentlicht und zitiert. Dagegen gehen unspektakuläre oder negative Ergebnisse oft unter. Aber:
- es gibt Hinweise, dass sich jenes alte Muster wiederholt, demnach neue Technik denen nützt, die bereits eine gute Vorbildung haben, während weniger gut Gebildete davon kaum oder gar nicht profitieren bzw. sogar Nachteile erleiden.
Und nun?
Es braucht standardisierte Analysen und Langzeitstudien.
Klar ist aber auch: alle bisherigen und aktuellen politische Entscheidungen basieren auf Vermutungen und Wunschdenken.
Kurzum: Es gibt noch viel zu tun. Bis dahin aber, so fürchte ich, werden die Horror- und Heilsgeschichten-Erzähler weiterhin ihre Thesen an die Türen der Bildungseinrichtungen zu nageln versuchen...
4. Februar 2026
Google hat die Recherche versaut.
ChatGPT erledigt den Rest.
Es ist Zeit, etwas dagegen zu tun!
Bevor KI kam, hatten die Hochschulen ein dickes Recherche-Problem. Und das sah so aus:
- die meisten Studierenden googelten lieber, statt Bibliothekskataloge und Fachdatenbanken zu nutzen
- Repositorien klangen wie Latein und wurden wie Latein behandelt – mit respektvoller Ignoranz
- "Phrasensuchen", Trunkierung* und Boolesche Operatoren waren AND/OR egal
- was nicht auf Deutsch oder Englisch erschienen war, war im Grunde nicht erschienen
- statt systematischer Recherche dominierte eine "Ich habe was gefunden, das reicht"-Mentalität
- Forschungsfragen wurden in der Recherche so zielgerichtet eingesetzt wie eine Schrotflinte
- und ein Blick auf die 2. Seite der Trefferliste war eine Seltenheit
Kurzum: Google hatte alles versaut. Die Suchen waren kurz und beschämend oberflächlich.
Wer nur mit Google und ChatGPT recherchiert, übersieht viele Daten
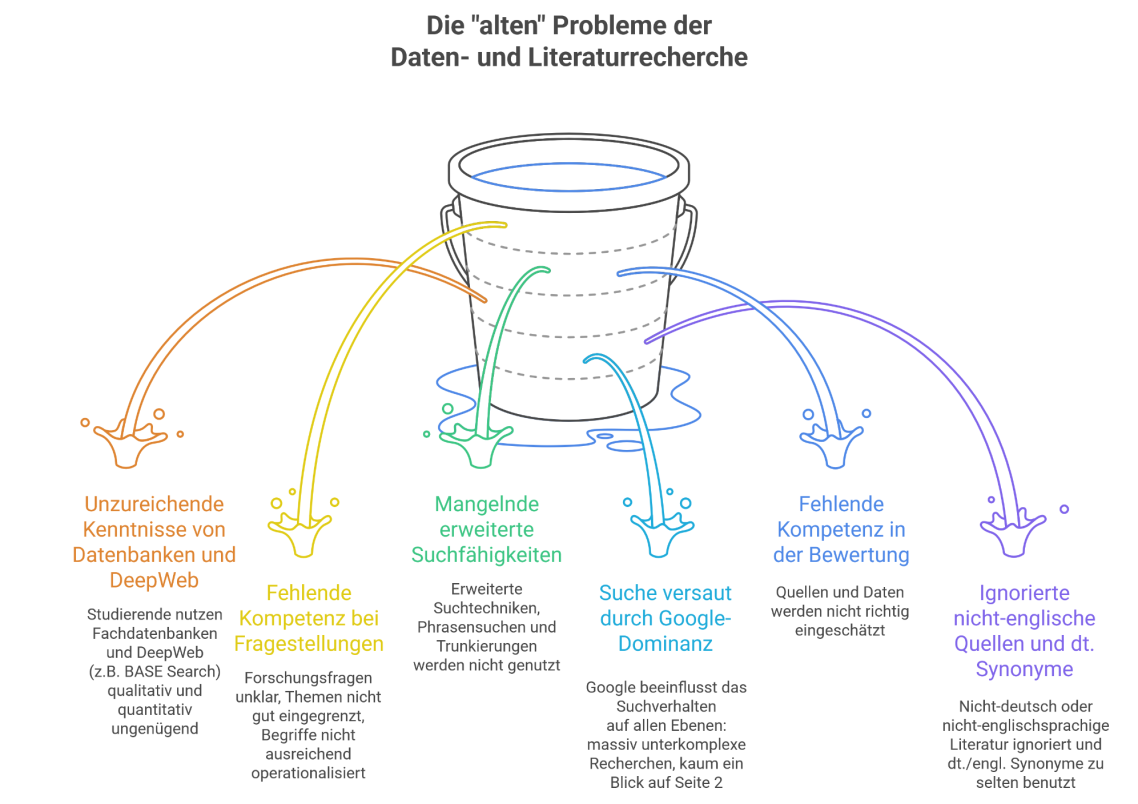
Dann kam KI. Das heißt: ChatGPT. Denn was anderes nehmen sie an den Hochschulen fast nicht. Dafür nehmen sie es aber für so ziemlich alles. Auch zur Recherche. "Chatty" wird's schon richten. Das sagen nicht nur die Studis, das denken auch viele Dozenten. (Der Rest schimpft auf KI oder zuckt mit den Schultern. Hilflos. Ahnungslos. Es ist im Grunde egal.)
In Wahrheit macht ChatGPT alles noch schlimmer. Es kaschiert die alten Defizite, indem es neue Probleme obendrauf packt.
Was also tun?
Anfangen, zeitgemäß zu recherchieren, würde ich sagen. Zum Beispiel so:
1. Wissenschaftsspezifische Recherche-KI-Tools nutzen: Es gibt über ein Dutzend, und sie sind verdammt gut darin, Studien zu finden und Daten zu erklären.
2. Fachdatenbanken (wieder) entdecken: Viele haben inzwischen eigene KI-Assistenten. Und im Gegensatz zu ChatGPT können die ihre Quellen auch nicht halluzinieren.
3. Tief in Repositorien eintauchen: Endlich die Forschungen der eigenen Hochschule nutzen und Wissensschätze aus fernen Ländern heben. Fremdsprachige Texte mit KI übersetzen, Daten extrahieren und alles gekonnt visualisieren.
4. Citation Tracking & semantische Cluster nutzen: Wer hat wen zitiert? Welche Themen hängen zusammen? KI-generierte Wissensgraphen erzeugen die schönsten Forschungslandkarten.
5. Alle Teile systematisch verbinden: Literatur, Daten, Quellen – alles miteinander verknüpfen und Workflows bauen, die einen durch Studium und Wissenschaft tragen. Und darüber hinaus.
Genau daran arbeite ich.
Man kann KI in den Suchschlitz kippen und hoffen,
dass beim Tippen Kompetenzen entstehen.
Oder man beginnt mit echter Recherchekompetenz
und integriert KI sinnvoll darin.
Als Rechercheur bin ich natürlich auch immer auf der Suche. In diesem Fall auch nach Auträgen für neue Recherche-Workshops.
Für die nächsten Monate habe ich noch Kapazitäten. Egal ob für Geistes-, Sozial- oder Naturwissenschaften, ob als Grundlagenschulung oder Vertiefungskurs, online oder vor Ort. Schreiben Sie mir einfach. Gern mache ich Ihnen ein Angebot.
Denn das neue Semester kommt schneller als man denkt. Und dann sitzen wieder alle da mit "Chatty", dem unzuverlässigsten aller Datenorakel.
2. Februar 2026
Zahl der KI-Betrugsfälle an Hochschulen wächst. KI-Detektoren versprechen Aufklärung.
Forscher und Juristen sehen das anders.
Ich habe den aktuellenStand der Dinge zum Thema KI-Erkennungs-Software (KI-Detektoren) mal für euch zusammengetragen. Es gibt inzwischen zahlreiche Studien, Rechtsgutachten und natürlich auch viel Praxiserfahrung dazu. Die Quintessenz lautet: Hände weg von KI-Detektoren!
Warum genau, das erfahrt ihr in meiner Analyse (PDF, Link) und auf meinen LinkedIn-Profil. Und wer mehr dazu lesen will, hier meine kleine Literaturliste zum Thema.
30. Januar 2026
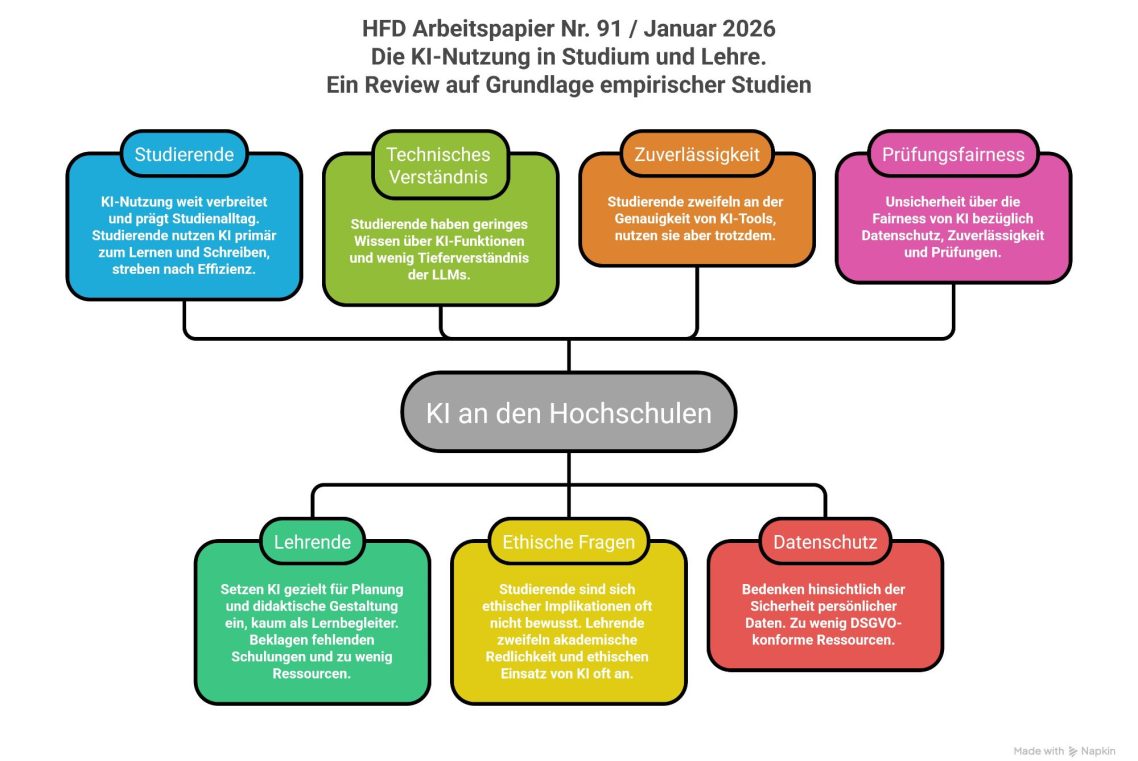
KI an Hochschulen: Studierende nutzen sie, Lehrende hinken oft hinterher, einen richtigen Plan hat keiner und fundierte Praxiserfahrung fehlt weitgehend.
Das ist natürlich pointiert ausgedrückt, aber in die Richtung geht's bzw. ist es bisher gegangen, weshalb das jetzt der zugespitzte Stand der Dinge ist.
Wer es genauer wissen will: Das Hochschulforum Digitalisierung (HFD) hat die Datenlage zum Thema "Die KI-Nutzung in Studium und Lehre" zusammengefasst und "Ein Review auf Grundlage empirischer Studien" dazu publiziert. Es ist gestern als Arbeitspapier erschienen und hier (Link) zu finden. Dicker Lesetipp!
Aber da ich weiß, dass nicht alle so viel Zeit haben (und manche lieber Infografiken anschauen) hab ich die zentrale Ergebnisse mit Hilfe von Napkin AI mal in einem Bild zusammengefasst.
29. Januar 2026
Du kannst deine Dateien synchronisieren, aber nicht die Gesellschaft. Oder: KI bringt die Zeit aus dem Takt.
Ich habe heute einen Beitrag von Christoph Jaschek auf LinkedIn gelesen, der davon handelt, dass man Probleme nie endgültig lösen kann und sich deshalb für die Lösung entscheiden sollte, deren Nachwehen man am ehesten ertragen kann.
Der Beitrag hat mich zum Nachdenken gebracht. Aber aus einem anderen Grund. Weil er sich auf einen 17 Jahre alten Text bezog und ich mich fragte, warum ein Text von 2009 "alt" auf mich wirkt. Er ist nämlich sehr aktuell. Besonders wenn ich auf die KI-Debatte schaue. Ich meine: viele Tools altern schneller als ein Joghurt ohne Kühlung. (Erst kürzlich schrieb Ronnie Parsons: „I just deleted 12 Claude PROJECTS. 3 Claude SKILLS replaced them all.“)

Die Beschleunigung, die KI mit sich bringt, führt dazu, dass das Tempo, mit dem sich die einzelnen Teil der Gesellschaft bewegen, immer wieder auseinanderklafft.
Mein Gedanke: Unser Empfinden von dem, was „alt“ ist, hat sich durch KI massiv verkürzt.
Meine These (und erst jetzt wird’s wichtig, das war bisher alles nur Vorrede, denn das hier ist kein KI-generierter Text, liebe Leute), also, jedenfalls meine These ist: KI bringt die gesellschaftlichen Zeitebenen aus dem Takt.
Der Soziologe Hartmut Rosa hat sinngemäß gesagt: Beschleunigung führt zu systemischer Desynchronisation. Heißt: Das Problem unserer Gesellschaft ist nicht das wachsende Tempo, sondern dass ihre Teilsysteme aus dem Takt geraten, weil sie verschiedenen Zeit-Rhythmen folgen. Das zeigt sich auch bei KI.
Auf der Mikroebene gibt es täglich neue Tools & Modelle.
Auf der Makroebene sieht es dagegen ganz anders aus: Bildungseinrichtungen, Behörden, große Unternehmen: reagieren nur im Jahrestakt. Höchstens quartalsweise. Aber sie bleiben strukturell langsam. Das ist an sich okay. Es wäre komisch, wenn sie mithetzen würden.
Das Problem ist die Mitte. Es ist die Ebene, auf der Gesellschaft Sinn produziert und sich stabilisiert. Diese Mitte ist die allgemeine Öffentlichkeit, sind Diskurse, Deutungsmuster, kollektive Selbstverständnisse. Die Mitte liegt zwischen den Tools und den Institutionen. Hier liegt die eigentliche Spannung. Und das große Problem.
Denn normalerweise werden die Konflikte zwischen Mikro und Makro von der mittleren Ebene moderiert und (dadurch) abgemildert. Aber das passiert nicht mehr. Denn wo früher Widersprüche ertragen und Bedeutungen ausgehandelt wurden, dominieren heute Moralisierung und Schuldzuschreibungen.
Das Ergebnis: die Mitte schwindet, wird nicht mehr gehört, ist (wirk-)ohnmächtig. So verliert eine Gesellschaft ihre Orientierung. Und dann ist Hochzeit für Apokalyptiker und Integrierte. Jedenfalls dominieren Gebrüll und Vorwürfe. Auf allen Seiten.
– hysterische KI-Debatten zwischen Paradies und Apokalypse
– strategische Unsicherheit hier, individueller Hype dort
Die spannende Frage ist nun: Wie kann die Mitte gestärkt werden? Wie kann sie die verschiedenen Geschwindigkeiten austarieren und die digitale Spaltung verlangsamen?
Darauf haben wir keine guten Antworten. Und das liegt auch daran, dass wir die falschen Fragen gestellt haben. Oder?
Bild: PXhere (Creative Commons Zero, Link)
28. Janar 2026
Schluss mit Recht auf Teilzeit? Oder nicht? Hier die Ergebnisse einer systematischen Literaturanalyse zum Thema Arbeitszeitverkürzung als Infografik,
2023 haben Wissenshaftler des Centre for Development and Environment der Universität Bern insgesamt 30 internationale Studien zum Thema Arbeitszeitverkürzung ausgewertet. (Link)
Die Daten sind zwar nicht 1:1 auf die aktuelle Debatte, vom CDU Wirtschaftsflügel ausgelöste Debatte um das Recht auf Teilzeitarbeit übertragbar, da Teilzeit nur eine Form von Arbeitszeitverkürzung darstellt, aber sie geben viele wertvolle Hinweise.
Die Frage der Forscher lautete: Wie wirken sich Arbeitszeitverkürzungen (z. B. 4‑Tage‑Woche oder 6‑Stunden‑Tag) sozial, ökonomisch und ökologisch aus?
Die Infografik zeigt die Ergebnisse. Ich habe sie mit Napkin AI erstellt.
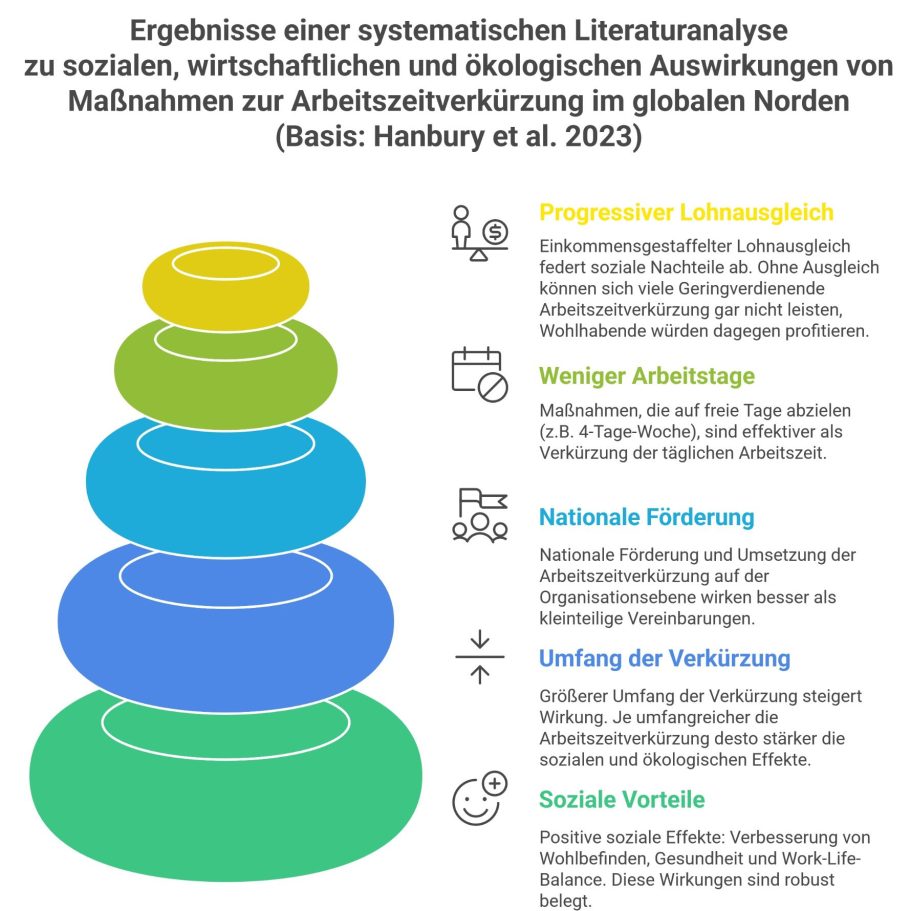
Die Auswertung zeigt, dass Arbeitszeitverkürzung bessere Gesundheit, weniger Stress und mehr Zufriedenheit bringt. Gleichzeitig wird deutlich, dass ökonomische und ökologische Effekte von der konkreten Ausgestaltung abhängen und mehr Forschung nötig ist.
Was bedeutet das konkret?
Ganz einfach: Arbeitszeitverkürzungen verbessern das subjektive Wohlbefinden, reduzieren Stress und Erschöpfung, verbessern die körperliche und mentale Gesundheit und entlasten die Vereinbarkeit von Beruf und Familie.
Die Effekte zeigen sich deutlich: Weniger emotionale Erschöpfung, weniger Konflikte auf Arbeit und in der Familie, besserer Schlaf.
Besonders Berufe mit hoher körperlicher Beslastung profitieren davon. Ebenso Geringverdiener und Frauen, besonders Mütter.
Wichtig auch: Je umfangreicher die Arbeitszeitverkürzung war (z.B. mindestens 6 Stunden pro Woche), desto stärker sind die sozialen und ökologischen Effekte. Kleine Verkürzungen zeigen dagegen kaum eine Wirkung.
Wenn Arbeitszeitverkürzungen durhch die Politik unterstützt werden, z.B. durch Gesetze oder Tarifverträge und in größerem Umfanh umgesetzt werden, ist die Effektivität besonders hoch. Individuelle Vereinbarungen bringen dagegen wenig.
Und: Maßnahmen, die auf ganze freie Tage abzielen (z.B. 4-Tage-Woche), sind effektiver als eine Verkürzung der Tagesarbeitszeit.
Und schließlich: Ein nach Einkommen gestaffelter Lohnausgleich (voller Ausgleich für Geringverdienende, geringerer für Besserverdienende) kann soziale Nachteile vermeiden. Geringverdiener könnten sich sonst Arbeitszeitverkürzungen bzw. Teilzeit nicht leisten.
Man beachte aber: Die Studie gibt keine Werturteile ab, ob man weniger arbeiten sollte. Sie analysiert die empirischen Wirkungen verschiedener Arbeitszeitverkürzungsmodelle. Die Forscher schreiben: "Die Evidenzbasis unserer Ergebnisse ist eventuell nicht solide genug, um klare politische Empfehlungen zu rechtfertigen, aber sie gibt uns die Möglichkeit, Arbeitshypothesen zu formulieren." (S. 13, meine Übersetzung)
Genau diese "Arbeitshypothesen" habe ich mit Hilfe der Infografik dargestellt.
Laut den Schweizer Forschern braucht es aber noch mehr Forschung. Und zwar zu folgenden Punkten:
Vergleich mehrerer Dimensionen: Studien sollten soziale, ökonomische und ökologische Effekte gemeinsam untersuchen, um Wechselwirkungen besser zu verstehen.
Vergleich verschiedener Modelle von Arbeitszeitverkürzung: Es fehlen Studien, die verschiedene Formen und Umfänge von Arbeitszeitverkürzung vergleichen. Hier wäre Teilzeit noch genauer zu untersuchen!
Kontexte & Subgruppen analysieren: Qualifikationen, Branche und Arbeitsbedingungen beeinflussen die Wirkung. Diese Variablen müssen systematischer berücksichtigt werden.
Ökologische Effekte: Es braucht mehr Studien, die die Umweltwirkungen von Arbeitszeitverkürzungen analysieren, z. B. CO₂-Ausstoß und Konsumverhalten. Die bisherigen Daten lassen leicht positive ökologische Effekte durch Arbeitszeitverkürzung erkennen.
Begleitmaßnahmen: Mögliche Lohnkompensationen sollten mit Blick auf die Einkommenshöhe näher erforscht werden, um soziale Gerechtigkeit und ökologische Effekte besser auszubalancieren.
Zeitverwendung neben Erwerbsarbeit: Der Einfluss von Care-Arbeit u.a. oft unbezahlten Tätigkeiten muss stärker erforscht werden.
Geschlechtsspezifische Effekte analysieren: Studien sollen die Wirkung von Arbeitszeitverkürzungen bzw. Teilzeit auf Männer und Frauen getrennt untersuchen, besonders bezüglich der Karrierechancen und Care-Arbeit.
So, und jetzt darf weiterdiskutiert werden 😉
Quelle: Hanbury, H., Illien, P., Ming, E., Moser, S., Bader, C., & Neubert, S. (2023). Working less for more? A systematic review of the social, economic, and ecological effects of working time reduction policies in the global North. Sustainability: Science, Practice and Policy, 19(1). https://doi.org/10.1080/15487733.2023.2222595
26. Januar 2026

Betrug mit KI an Schulen und Hochschulen wächst.
Ich habe mir in mal die Daten angeschaut, die Forscher aus aller Welt zum Thema "Betrug mit KI in Bildungseinrichtungen" veröffentlicht haben. Ich habe über 100 Paper gefunden (aber erst ca. 30 genauer gelesen).
Für Deutschland ist die Datenlage schwach. Verschiedene Unis berichten über Betrügereien, aber das betrifft immer nur die entdeckten Fälle. Es fehlen noch Übersichtsstudien, größere Umfragen etc. Immerhin gibt es erste qualitative Studien und Versuche, das Problem quantitativ zu erfassen.
Hier eine erste, absolut unvollständige Liste. Detaillierte Ergebnisse und Verlinkung auf alle Quellen später:
Studien zeigen erschreckende Ergebnisse.
USA: 75% der Psychologiestudenten berichteten, dass sie bei mindestens einem Leistungsnachweis mit KI-Hilfe geschummelt haben.
China: In einer Universität in Shanghai gaben 79% der 120 befragten Studierenden zu, bei Sprachprüfungen mit KI betrogen zu haben. (Link)
Großbritannien: Ein Experiment der University of Reading zeigte 2024, dass KI-generierte Prüfungsantworten in 94 % der Fälle unentdeckt blieben. Zugleich wurden 2023/24 an britischen Hochschulen fast 7.000 Betrugsfälle aufgedeckt, viele davon KI bedingt. Für 2024/25 werden 11.000 Fälle geschätzt, Tendenz weiter stark steigend. (Link)
Ecuador: Forscher stuften in einer Studie von 2025 das KI-NUtzungsverhalten von 51% der Studenten als "Betrug" ein. (Link)
Saudi-Arabien: Die Häufigkeit der Nutzung von ChatGPT ist mit signifikant mit höheren Betrugsraten verbunden. (Link)
Türkei: eine Übersichtsstudie erklärt: "Das betrügerische Verhalten der Studierenden hat ein Ausmaß erreicht, dass die akademische Ehrlichkeit grundlegend beeinträchtigt ist."
Mexiko: Eine Studie von 2025 zeigt, dass Studenten, die merken, dass ihre Kommilitonen mit KI betrügen, ihr (künftiges) betrügerisches Handeln damit rechtfertigen.
Spanien: Eine Studie (2025) erkennt eine um sich greifenden Betrugskultur, wodurch die Motivation sinkt, weiter ohne KI zu arbeiten bzw. nicht zu betrügen. Die Folge: auch hier stark steigende Betrugsraten.
Norwegen: die zehn größten Hochschulen des Landes melden eine Verdoppelung der KI-Betrugsfälle von 2024 zu 2025. (Link)
USA & Kanada: 2024 waren in einer großangelegten Umfrage 96% aller Uni-Dozenten davon überzeugt, dass ein Teil ihrer Studenten mit Hilfe von KI betrügt. Zudem waren sich 53% der Studenten sicher, dass die Betrugsfälle stark zugenommen haben. Alle erwarteten weitere Steigerungen.
Deutschland: Eine Studie von 2025 fand bei 38 von 256 Studenten KI-Betrug. (Link) Und nach Interviews mit Studierenden stellten deutsche und norwegische Forscher 2024 fest: "Die Studierenden gaben zahlreiche unterschiedliche Formen des betrügerischen Gebrauchs von KI-Chatbots preis." (Meine Übersetzung, Link)
Mit den Betrügereien gehen natürlich viele andere Probleme einher. Aber dazu später mal mehr. Ich wollte hier erstmal einen Zwischenstand geben.
Fragen, Anmerkungen, Interesse an bestimmten Daten gern an mich.
Bildquelle: Wikimedia
25. Januar 2026
Der Wissenschaftshistoriker Thomas S. Kuhn prägte 1962 in seinem Buch “The Structure of Scientific Revolutions” den Begriff “Paradigmenwechsel” (paradigm shift).
Kuhn beschrieb damit wissenschaftliche Revolutionen dahingehend, dass sich fundamentale Rahmenwerke der Wissenschaft (Fragestellungen, Methoden, Erklärungen) grundlegend geändert haben.
Es ist also kein Paradigmenwechsel, wenn jemand von ChatGPT zu Claude wechselt oder Apple eine Partnerschaft mit Google eingeht!
PS: Kuhn nutzte den Begriff auf 200 Seiten nur 6 Mal. Heute liest man ihn in 6 LinkedIn-Beiträgen 200 Mal.
Bild: nicht KI-generiert
Quelle: https://lnkd.in/gX8j2kDF
23. Januar 2026
Paradigmen werden häufiger gewechselt als Unterhosen

Großartige Neuigkeiten!
SciSpace AI hat mich gefragt, ob ich ein Webinar fürs deutsche Publikum machen will!
Es geht um einen praktischen Leitfaden zum Einsatz von KI in Wissenschaft, Studium und Forschung. Und da ich SciSpace regelmäßig nutze und das Tool sehr mag, hab ich natürlich Ja gesagt.
Also, wer SciSpace noch nicht kennt und mal schauen will, was man mit KI im Bereich Wissenschaft und Wissensarbeit so alles machen kann: einfach digital vorbeischauen!
Datum: Mittwoch, 11. Februar 2026
Zeit: 16:00 - 17:00 Uhr via Zoom
Sprache: das Webinar findet auf Deutsch statt
Es wird eine Einführung in Sci Space AI, Best-Practice-Beispiele und Live-Demos geben.
Danach besteht natürlich die Möglichkeit, Fragen zu stellen.
Alle Infos und die kostenfreie Anmeldung gibt's hier:
https://luma.com/o1vf4u1a
Gern teilen und weitersagen.
Ich freue mich auf euch!
Das Original weiß, dass es kopiert!
Es ist ein komischer Gedanke, aber ich glaube, die guten alten Plagiate sterben aus. KI hat die Kultur des heimlichen Abschreibens ebenso heimlich abgeschafft. Das klassische Plagiat ist abgeschrieben, sozusagen.
Die halbe Welt schreibt ihre Texte jetzt mit KI - und die andere Hälfte fahndet danach. Aber kaum jemand macht mehr Plagiate. Klar, warum auch?! Es ist viel leichter sich einen Text von der nächstbesten KI generieren zu lassen als einen Text irgendwo rauszukopieren oder - nicht auszudenken - ihn vielleicht sogar noch eigenhändig umzuschreiben.
Klar, auch das KI-generierte Textgematsche ist eine Form des Plagiats und wird auch so bezeichnet, aber es ist eine neue Form, eine, die sich vom klassischen Plagiat unterscheidet, qualitativ und - vor allem - quantitativ.
Dazu passt, dass zwar alle Welt über die KI-Texte forscht und berichtet, aber über die klassische Plagiat-Macherei wird im Zeitalter von KI-Texten kaum noch geschrieben.
Ich musste eine Weile suchen, um empirisch zumindest einigermaßen belastbares Material zu finden. Eine großangelegte Befragung britischer Universitäten vom Mai 2025 ergab folgendes Bild. Ich zitiere - übersetzt - aus dem "Guardian", der die Untersuchung durchgeführt hat.
"In den Jahren 2019-20, bevor generative KI weit verbreitet war, machten Plagiate fast zwei Drittel aller akademischen Verfehlungen aus. Während der Pandemie nahmen Plagiate zu, da viele Prüfungen online stattfanden. Mit der zunehmenden Verbreitung und Verbesserung von KI-Tools hat sich jedoch die Art des Betrugs verändert. Die Umfrage ergab, dass die bestätigten Fälle von traditionellem Plagiaten von 19 pro 1.000 Studenten auf 15,2 im Jahr 2023-24 zurückgegangen sind und nach ersten Zahlen aus diesem akademischen Jahr voraussichtlich auf etwa 8,5 pro 1.000 sinken werden."
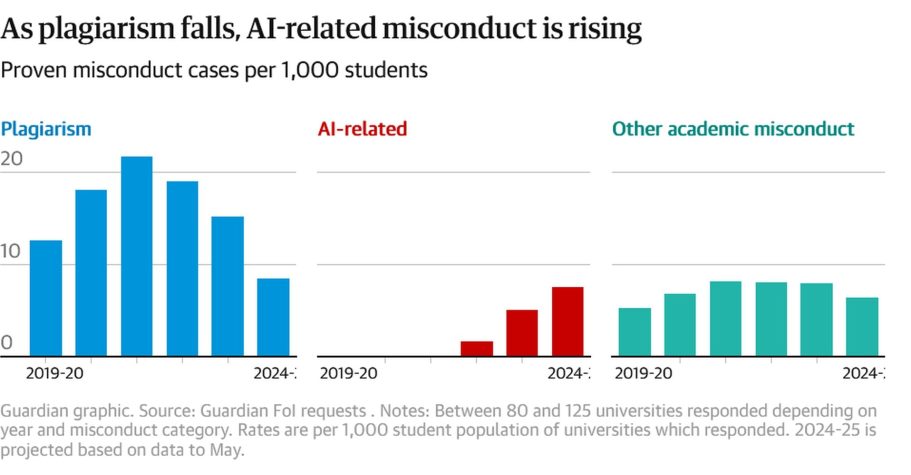
Andererseits, vielleicht ist die Tatsache, dass sich kaum noch jemand im Plagiieren übt und auch fast niemand mehr drüber berichtet, weil alle panisch nach KI-Nutzung suchen (und die Plagiatsjäger nur über dahingeklatschten Politiker-Promotionen von anno dazumal hocken), vielleicht ist all das ja die Rettung der guten alten Kultur des Plagiierens. Ein plötzlicher Freiraum, in welchem die traditionelle Methode des Abschreibens aufs Neue erblühen kann?!
Ich weiß, man sollte das nicht romantisieren. Aber wenn so ziemlich jeder bekannte Schriftsteller - von Shakespeare über Goethe bist Brecht - die Kultur des Plagiats gepflegt hat, liegt die Romantik nunmal näher als die Empörung. Manche haben es heimlich getan, andere offen.
Wie Brecht, der den Vorwurf, er habe in seiner "Dreigroschenoper" von François Villon abgeschrieben, ins Leere laufen ließ, indem er erklärte: „Nehm jeder sich heraus, was er grad braucht! Ich selber hab mir was herausgenommen.“
In diesem Sinne: Frohes Plag(iier)en 😊
22. Januar 2026
Wie der KI-Einsatz in Staat und Verwaltung das Vertrauen in demokratische Institutionen zerstört. Und was Donald Trump damit zu tun hat.
Also, die Sache ist die: wenn ich wüsste, worauf es hinausläuft, wenn ich über ein Thema zu schreiben beginne, könnte ich es auch lassen. Denn Schreiben ist nicht das Wiedergeben von Gedanken, sondern das Erschaffen derselben. Es ist kein Spiegel der Erkenntnis, es ist der Erkenntnisprozess selbst.
Ich fürchte allerdings, dass KI da nicht mitmacht bzw. diese Herangehensweise kollektiv versaut, ganz einfach deshalb, weil viele ihre Texte von KI vorschreiben lassen und nur noch "Feinschliff" machen. Als könnte man eine missratene Marmorskulptur mit etwas Sandpapier retten.
Geschenkt. Was in meinem Kopf kreißt (und vielleicht nur ein Berg ist, der ein Mäuschen gebiert) sind zwei Dinge, die erstmal nichts miteinander zu tun haben. (Aber ist es nicht oft so, dass zwei unabhängig voneinander verlaufende Entwicklungen sich zufällig treffen und fortan gemeinsame Sache machen, einfach nur, weil sie von zwei Seiten auf dieselbe Hauptstraße abgebogen sind?)
Jedenfalls, das erste „Ding“ war die unten abgebildete eine Grafik. Sie zeigt, um welche Themen sich Trump vorrangig kümmert. Und siehe da: Die Untergrabung demokratischer Institutionen gehört für ihn zum Kerngeschäft. (Hier der Link).
Trump und seine Leute höhlen den Staat systematisch aus
und füllen danach die Leere mit ihrer Autorität.
Das zweite „Ding“, das in meinem Kopf war, hat damit nichts zu tun, denn es sind Studien, und jemand wie Trump liest keine Studien. Er liest gar nichts, was länger als ein Truth-Social-Posts ist. Aber gut, die Studien untersuchen jedenfalls den Einsatz von KI in Staat und Verwaltung und kommen zu dem Schluss, dass KI zwar mehr Effektivität bringt, nur wird die teuer bezahlt, nämlich mit einem Verlust an Glaubwürdigkeit, Vertrauen und Akzeptanz in genau diese Institutionen. Und das umso mehr, wenn die Institutionen als ungerecht, kaputt und /oder politisiert wahrgenommen werden. (Hier der Link zu drei Studien bzw. Mety-Analysen: Link 1 / Link 2 / Link 3)
Heißt: Die KI kann noch so gut Ergebnisse liefern, sie wird trotzdem als negativ wahrgenommen, denn Menschen beurteilen nicht das Ergebnis, sondern das Verfahren. Und wenn das automatisiert abläuft, wird es tendenziell als unfair und entmenschlicht betrachtet. Und dieses Bild wird zurück auf die Institution projiziert.
Genau da haben sich die zwei Stränge in mir zu einer Frage zusammengefügt: Wenn in so einem politischen Klima KI in Staat und Verwaltung eingeführt wird, trifft sie dann nicht auf eine kaputte Vertrauenslandschaft? Nicht nur in den USA, sondern auch hierzulande, wo die Polarisierung ebenfalls wächst? Als These formuliert: KI wird dann nicht als Fortschritt wahrgenommen, sondern als weiterer Beleg dafür, dass Entscheidungen nicht nachvollziehbar sind und noch ungerechter wirken als zuvor.
Mit anderen Worten: Wenn wir in Staat und Verwaltung nach KI rufen müssen wir uns fragen, auf welche Welt und – vor allem – auf welche Wahrnehmung von Welt die KI trifft. Es könnte für ihren Erfolg wie für ihren Misserfolg entscheidend sein.
21. Januar 2026
Halluzinierende Anwälte. Ich habe mal ausgewertet, in wie vielen Gerichtsverfahren Künstliche Intelligenz für Chaos gesorgt hat. (Es sind viele!)
Der Fall ging durch die Medien: das Landgericht Darmstadt hat einem Professor das Honorar gestrichen, weil sein "Gutachten" (das Gericht selbst setzte den Begriff in Anführungszeichen) von KI generiert und so fehlerhaft war, dass es vor Gericht nicht verwendet werden konnte (Az.: 19 O 527/16, Urteilsbegründung)
Solche Fälle machen Schlagzeilen. Aber fast niemand schaut dahinter, denn KI-generierte Gutachten, erfundene Fälle und falsche Rechtsbelege sind kein Einzelfall. Ich habe mir deshalb die Sache mal systematisch angesehen und mit Hilfe von Excelmatic.ai einen Datensatz ausgewertet, der welweit 811 Fälle von KI-Halluzinationen in Gerichtsverfahren gesammelt hat. Hier die Webseite dazu.
In über 800 Fällen basierten Gerichtsverfahren auf KI-generierten Fehlinformationen. Die Dunkelzifffer ist um ein Vielfaches höher.
Wichtig zur Einordnung der Zahlen:
1.) Manche Fälle enthalten mehrere Arten von Halluzinationen, z.B. erfundene Urteile und falsche Zitate. Deshalb ist die Gesamtzahl an Haluzinationen in meiner Auswertung deutlich höher als 881.
2.) Mitunter sind in einem einzigen Schriftsatz drei oder vier Fälle einer Halluzinationsart, z.B. erfundene Urteile, enthalten.
Die Zahlen zeigen: KI sorgt (nicht nur) für falsche Details, sondern für grundlegende Fehler. Das Muster ist deutlich: Das Gros der Probleme betrifft:
- von KI komplett erfundene Gerichtsentscheidungen: 1338 Fälle
- durch KI falsch dargestellte Rechtsprechung: 581 Fälle
- von KI erfundene oder falsche Zitate: 451 Fälle
Dazu kommen andere Nonsens-Belege.
Das Erschreckende: das sind keine einzelnen Ausrutscher. Vielmehr scheinen KI-Halluzinationen in juristischen Kreisen zu einem generellen Problem zu werden. Die Dunkelziffer dürfte jedenfalls wesentlich höher als die in der Datenbank aktuell versammelten 811 Beispiele liegen.
Wer weiß, wie viele Menschen auf Grundlage fiktiver Fälle verurteilt wurden, weil niemand die Sache nachgeprüft hat.
Das Problem ist dabei nicht, dass KI Fehler macht. Das Problem ist vielmehr, dass diese Fehler nicht erkannt werden, weil Anwälte und andere Rechtsvertreter die Quellen nicht prüfen. Im Falle des oben genannten Professors hatte das Gericht in Darmstadt erklärt, es habe "nicht einmal eine Untersuchung der Klägerin stattgefunden", zudem wurde "ein Unfallgeschehen herangezogen [...], dass sich so nicht einmal nach der Darstellung der Klägerin ereignet hat."
Und was lernen wir daraus?
Die Basis jeder guten Entscheidung sind gute, saubere Daten. Das gilt für Gerichtsakten genauso wie für Entscheidungen, die in Unternehmen getroffen werden. KI kann bei der Recherche helfen, aber nur, wenn sie richtig eingesetzt wird. Eine kritische Überprüfung der Ergebnisse ist unerlässlich. Und die Kenntnis der richtigen Tools. Und da gibt es deutlich besseres als ChatGPT.
KI-Bildung heißt deshalb zuerst: richtig recherchieren lernen. Ich stehe mit meiner Expertise dafür gern zu Verfügung.
20. Januar 2026
KI-Spaltung zwischen Ost und West. LLMs voller Vorurteilen, unschöne Daten und eine harte Frage.
Um eins vorwegzunehmen: das Folgende ist ein Abtasten des Feldes. Es soll Basis für Diskussion, Daten, Denkanstöße sein.
1.) Eine Studie hat gezeigt, dass LLMs die Ost-Bundesländer negativer bewerten bei Intelligenz, Offenheit gegenüber Neuem usw. Die ostdeutschen Bundesländer bekamen in allen Kategorien geringere Werte, egal, ob die Zuschreibungen positiv, negativ oder neutral waren. Ergebnis: bei Fleiß und Faulheit waren die Werte jeweils niedriger, Ostdeutsche also weniger fleißig und faul zugleich. Erklärung: das LLM hat aus seinen Trainingsdaten "gelernt", dass Ostdeutschland statistisch häufiger mit niedrigen bzw. minderwertigen Bewertungen assoziiert wird. Diese Bias lässt sich auch durch "Debiasing Prompts" kaum auflösen. Die Forscherinnen kommen zu dem Schluss: "Wir stellen fest, dass es eine statistisch signifikante Tendenz gibt, dass die Bundesländer im Osten schlechter bewertet werden als die anderen". (S. 12, meine Übersetzung).
2.) Eine weitere Studie von 2025 bestätigt die bekannte digitale Spaltung zwischen Ost und West und zeigt, dass es diese Spaltung auch beim KI-Einsatz gibt. Die Unterschiede werden durch das Stadt-Land-Gefälle im Osten weiter verschäft. Bei technischer Infrastruktur und Integration digitaler Technologien, der Bereitstellung elektronischer Dienste und der (Wahrscheinlichkeit der) Einführung von KI in der öffentlichen Verwaltung liegen die ostdeutschen Bundesländer hinten.
3.) Eine Umfrage unter 500 IT-Entscheidern von Juli 2025 zeigt: im Osten nutzen 48% der Unternehmen noch keine KI, im Westen nur 28 Prozent. (siehe Bild) Fazit: "Während Unternehmen im Westen zunehmend auf KI setzen, hemmen im Osten Misstrauen und strukturelle Defizite die Transformation. [...] Wenn wir nicht gegensteuern und der Osten schnell nachzieht, riskieren wir eine digitale Zwei-Klassen-Wirtschaft.“
Ost- und Westdeutschland sind beim Thema Künstliche Intelligenz gespalten: technisch, finanziell und sozial.
4.) Misstrauen als Stichwort: Als "KI-Mensch" aus dem Osten, der teilweise auf dem sächsischen Land lebt, weiß ich, wie groß hier das Misstrauen in KI ist. Das ist ein Problem. Andersherum gibt es aber eventuell(!) auch ein Problem, das ich bewusst als Frage formuliere: "Kann es sein, dass Ostdeutschen weniger KI-Kompetenz zugesprochen wird als Westdeutschen?" Überspitzt und mit Blick auf mich selbst formuliert: Warum einen Einzelkämpfer aus Sachsen für KI-Workshops buchen wenn man eine fancy Agentur aus dem Westen haben kann?
19. Januar 2026

Wie KI bei Wissensrecherchen für Scheinkonsens sorgt & was dagegen getan werden kann.
KI-Recherche-Tools helfen, schnell einen Überblick zu einem Thema zu bekommen. Leider erzeugen sie dabei oft einen Scheinkonsens. Wo eigentlich Zweifel und Alternativen aufscheinen sollen, werden sie zu oft unter einer sprachlichen Konsenssoße begraben.
Wie sich das genau zeigt, warum das so ist und was man dagegen tun kann erfahrt ihr hier in diesem PDF oder direkt auf meinem LinkedIn-Profil.
Achja, Workshops und Schulungen zum Thema mache ich auch 😉

Ich habe mir einen Faktenchecker gebaut und ihr könnt ihn haben.
Okay, ich geb's zu, die Idee stammt nicht von mir: Das Team von snipKI hat in einem seiner Tutorials einen Faktenchecker erstellt. Der ist ganz gut, aber macht braucht Claude in der Bezahlversion, um ihn nutzen zu können.
Weil ich Claude nicht abonniert habe, habe ich mir den Faktenchecker für ChatGPT nachgebaut (Link). Ich weiß, da braucht man für die Nutzung auch ein Abo, aber ChatGPT haben mehr in der Bezahlversion als Claude.
Mein Faktenchecker ist noch nicht perfekt, aber liefert schon echt gute Ergebnisse. Die Anweisung "Faktencheck" und ein Link, ein Text oder eine Datei reichen für eine erste Übersicht zum Wahrheitsgehalt. Dann kann man tiefer gehen und wissenschaftliche Quellen, Datenbanken und Archive nutzen.
Wer den Faktenchecker für Mistral haben will, kann mir gern eine Mail schreiben oder mich auf LinkedIn kontaktieren. Und jetzt: Viel Spaß beim Fakten checken!
15. Januar 2026

Deutsche Gedenkstätten gegen KI-Fake-Bilder
Deutsche Gedenkstätten haben am 13.01.2026 einen Offenen Brief geschrieben. "Konsequentes Vorgehen gegen KI-generierte Holocaust-Verfälschungen auf Social-Media-Plattformen". (Link)
Darin warnen sie zurecht vor der massenhaften Verbreitung KI-generierter Holocaust-Bilder und frei erfundener NS-Geschichten in sozialen Medien. Die KI-Bilder und Videos setzen auf Emotionalisierung. Das Ziel sind nicht Bildungsarbeit und Aufklärung, sondern Klicks und Werbeeinnahmen. Die Folge sind Opfer-Täten-Umkehrungen, die Verwässerung historischer Fakten und Geschichtsrevisionismus.
Die Kritik ist vollauf berechtigt, doch sie hat Lücken.
Die Arbeit von Gedenkstätten und anderen Einrichtungen wird damit konterkariert, die Leidensgeschichten von Überlebenden und ihren Nachkommen werden ausgebeutet. Die Gedenkstätten fordern deshalb:
- ein pro-aktives Vorgehen der Plattformen gegen geschichtsverfälschende KI-Inhalte und Meldemöglichkeiten
- Ausschluss von Accounts von Monetarisierungsprogrammen
- Kennzeichnungspflicht für KI-generierte Inhalte
- Zusammenarbeit mit Experten
Das ist alles gut und richtig und dringend nötig.
ABER mir fehlt in diesem Offenen Brief einiges.
1. Es mangelt an einem "Wir selbst werden..."-Ansatz. Proaktiv müssen alle werden, nicht nur die Plattformen.
2. Es stellt sich die unbequeme Frage: Warum wirken emotionale Fake-Inhalte mehr als Originalmaterial? Liegt die Attraktivität der KI-Bilder "nur" an Emotionalisierung und den Algorithmen? Oder auch daran, dass historische Bildungsarbeit oft zu akademisch und zu unemotional daherkommt?
3. Welche Gegenmaßnahmen funktionieren (auf Social Media)? Positive Beispiele können zeigen, dass Gedenkstätten & Historiker Lösungen anbieten können.
4. Der Offene Brief nennt ein Problem, das viele fast täglich sehen. Aber was fehlt, sind Zahlen: Wie groß ist das Problem wirklich? Was sagen Studien zur Wirkung aufs Geschichtsverständnis? Erste Studien gibt es übrigens, z.B. hier, hier und hier .
Ergebnis der bisherigen Forschung:

- KI-Fake-Bilder von historischen Ereignissen führen zu false memories und politischer Polarisierung
- Menschen mit geringer Medien- und Geschichtskompetenz sind besonders anfällig
- KI-affine Teilnehmer erkannten Fälschungen klar besser (die Jüngeren waren oft besonders gut)
- es braucht KI-Bildung und Tool-Kenntnis fürs Erkennen der Fälschungen und Gegenmaßnahmen, dazu automatisierte Bildprüfungen usw.
IEs ist nur ein Gedanke, aber: Vielleicht muss man die KI-Fake-Bilder mit ihren eigenen emotionalen (aber nicht mit gefakten!) Mitteln bekämpfen.
14. Januar 2026

Eine kurze Geschichte der Künstlichen Intelligenz
Ich habe eine kleine, "illustrierte" Geschichte des Begriffs Künstliche Intelligenz (artificial intelligence) geschrieben. Das Ergebnis hat mich überrascht.
Die Geschichte beginnt bereits 1792 im Buch eines gewissen Proclus Diadochus:
Bd. 2, London 1792. Dort ist auf S. 47 (wahrscheinlich) erstmals von "artificial intelligence" die Rede.
Aber ich will nicht zu viel verraten. Die ganze Geschichte ist auf meinen LinkedIn-Profil zu finden. Und hier gibt es sie als PDF-Datei. Viel Spaß damit.
13. Januar 2026


Als der Rock 'n' Roll mit der KI zu tanzen begann. Und warum alle verrückt dadurch wurden.
1955 wurde der Begriff "artificial intelligence" geprägt. Parallel entstanden noch mehr Wörter, die ein faszinierendes Bild von der Zukunft der Gegenwart zeichnen. Eine kleine Zeitreise...
Es ist bekannt, dass der Begriff "artificial intelligence" in dem Sinne, wie wir ihn heute verwenden, 1955 vom Logiker John McCarthy geprägt wurde. McCarthy verwendete ihn in einem Förderantrag für eine Konferenz. ("We propose that a 2 month, 10 man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College in Hanover, New Hampshire.") Die Konferenz gilt gemeinhin als Initialzündung für die wissenschaftliche Beschäftigung mit KI.
Aber was passiert, so habe ich mich gefragt, wenn man einmal quer durch das Geburtsjahr des Begriffs "artificial intelligence" schneidet und sich anschaut, welche Begriffe im Jahr 1955 noch geprägt worden sind? Das Ergebnis ist faszinierend.
1955 ist das Jahr, in dem sich die moderne Welt als System zu beschreiben beginnt. Die Hochphase des Kalten Krieges spiegelt sich in der Sprache. Es geht ums Überleben, um Abschreckung, Kontrolle und Technik.
1955 entstanden nämlich auch die Begriffe "computer science", "information science", "home computer", "data file" und "microminiaturization". Es ist, als würde man durch ein Zeitfenster aus der Lochkartenwelt in die Zukunft schauen. Tatsächlich aber sind diese Begriffe ein Kind ihrer Zeit, denn 1955 beherrschten Kybernetik und Systemtheorie die wissenschaftliche Agenda. Kein Wunder, dass der "technophile" 1955 erstmals sein Haupt hebt. Es ist das Jahr, in dem sich die moderne Welt als System zu beschreiben beginnt.
Doch dieses System ist verwundbar, genau wie die Menschen, weshalb die Begriffe "stress test", "fallout shelter" und "intensive care unit" geprägt werden.
Auch in der Naturwissenschaft und der Industrie wird die Welt neu definiert. Begriffe wie "animal model", "base pair", "agribusiness" und "profit center" entstehen. Auch die "solar cell" scheint 1955 erstmals auf. Und wer's richtig heiß mag, erfeut sich am neuen "microwave ofen".
Technik, Biowissenschaften, Big Business und große Gefahr - fehlen nur noch das Militär und die mit ihm verbundene Raumfahrt. Und siehe da: 1955 ist auch ihr Jahr. Die Worte "aerospace", "special forces" und "cosmonaut" werden aus Buchstaben zusammengestanzt.
Die Hochphase des Kalten Krieges spiegelt sich in der Sprache. Es geht ums Überleben, um Abschreckung, Kontrolle und Technik. Doch wie immer ist die Gegenbewegung nicht weit. 1955 ist auch das Jahr von "do it yourself" und "New Left", die gemeinsam von "nonfossil" und "nonleaded" Treibstoffen träumen.
So gesehen ist es normal, dass parallel zur "artificial intelligence" auch das Wort "weirdo" entsteht. Für manch einen war der begrifflich wie musikalisch gleichzeitig entstehende "Rock 'n' Roll" bevölkert von solchen "Verrückten." Auch die Wissenschaft fand neue Begriffe und sprach von "schizoid personality disorder". Auch "intellectually disabled" taucht 1955 erstmalig auf.
Wenn es stimmt, dass Worte der Index von dem sind, was eine Gesellschft wahrnimmt, dann war 1955 ein sehr aufmerksames Jahr.
PS: Meine Quelle war die wunderbare "Zeitreise-Maschine" des Merriam-Webster-Dictionary (Link)
12. Januar 2026
12. Januar 2026
Als der Rock 'n' Roll mit der Künstlichen Intelligenz zu tanzen begann. Und warum alle verrückt dadurch wurden.
1955 wurde der Begriff "artificial intelligence" geprägt. Parallel entstanden noch mehr Wörter, die ein faszinierendes Bild von der Zukunft der Gegenwart zeichnen. Eine kleine Zeitreise...
Es ist bekannt, dass der Begriff "artificial intelligence" in dem Sinne, wie wir ihn heute verwenden, 1955 vom Logiker John McCarthy geprägt wurde. McCarthy verwendete ihn in einem Förderantrag für eine Konferenz. ("We propose that a 2 month, 10 man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College in Hanover, New Hampshire.") Die Konferenz gilt gemeinhin als Initialzündung für die wissenschaftliche Beschäftigung mit KI.
Aber was passiert, so habe ich mich gefragt, wenn man einmal quer durch das Geburtsjahr des Begriffs "artificial intelligence" schneidet und sich anschaut, welche Begriffe im Jahr 1955 noch geprägt worden sind? Das Ergebnis ist faszinierend.
1955 entstanden nämlich auch die Begriffe "computer science", "information science", "home computer", "data file" und "microminiaturization". Es ist, als würde man durch ein Zeitfenster aus der Lochkartenwelt in die Zukunft schauen. Tatsächlich aber sind diese Begriffe ein Kind ihrer Zeit, denn 1955 beherrschten Kybernetik und Systemtheorie die wissenschaftliche Agenda. Kein Wunder, dass der "technophile" 1955 erstmals sein Haupt hebt. Es ist das Jahr, in dem sich die moderne Welt als System zu beschreiben beginnt.
Doch dieses System ist verwundbar, genau wie die Menschen, weshalb die Begriffe "stress test", "fallout shelter" und "intensive care unit" geprägt werden.
Auch in der Naturwissenschaft und der Industrie wird die Welt neu definiert. Begriffe wie "animal model", "base pair", "agribusiness" und "profit center" entstehen. Auch die "solar cell" scheint 1955 erstmals auf. Und wer's richtig heiß mag, erfeut sich am neuen "microwave ofen".
Technik, Biowissenschaften, Big Business und große Gefahr - fehlen nur noch das Militär und die mit ihm verbundene Raumfahrt. Und siehe da: 1955 ist auch ihr Jahr. Die Worte "aerospace", "special forces" und "cosmonaut" werden aus Buchstaben zusammengestanzt.
Die Hochphase des Kalten Krieges spiegelt sich in der Sprache. Es geht ums Überleben, um Abschreckung, Kontrolle und Technik. Doch wie immer ist die Gegenbewegung nicht weit. 1955 ist auch das Jahr von "do it yourself" und "New Left", die gemeinsam von "nonfossil" und "nonleaded" Treibstoffen träumen.
So gesehen ist es normal, dass parallel zur "artificial intelligence" auch das Wort "weirdo" entsteht. Für manch einen war der begrifflich wie musikalisch gleichzeitig entstehende "Rock 'n' Roll" bevölkert von solchen "Verrückten." Auch die Wissenschaft fand neue Begriffe und sprach von "schizoid personality disorder". Auch "intellectually disabled" taucht 1955 erstmalig auf.
Wenn es stimmt, dass Worte der Index von dem sind, was eine Gesellschft wahrnimmt, dann war 1955 ein sehr aufmerksames Jahr.
10. Januar 2026
Macht KI uns dümmer? Oder schlauer? Wahrscheinlich sind das die falschen Fragen!
Die Studienlage wirkt(!) widersprüchlich.
1.) Viele Arbeiten zeigen: Mit KI schreiben Menschen bessere Texte, produzieren mehr Ideen, lösen Aufgaben schneller. Die Schlagworte, in diesem Zusammenhang völlig zurecht nennen, lauten "Upskilling" und "Newskilling" (nicht zu verwechseln mit "news killing" 🙃) Jedenfalls: Die Leistung steigt durch KI. Nicht überall und nicht bei allen gleich, denn bei Menschen mit mehr (KI-)Vorbildung steigt sie oft stärker, aber der Teufel scheißt nunmal auch in der digitalen Welt auf den größten Haufen.
2.) Andere Studien zeigen: Durch KI werden Menschen unkritischer, prüfen weniger nach, büßen Fähigkeiten ein. Das Schlagwort hier: Deskilling. Kompetenzverlust.
1 UND 2 sind gut belegt und stimmen auf ihre Weise. Aber die öffentliche Debatte (und hier auf LinkedIn) tut so, als gäbe es nur eine Frage: Macht uns KI schlauer oder dümmer? Das ist die falsche Frage, denn wenn man die Daten genau anschaut, lautet der Schluss: KI macht uns schlauer, aber auch insofern dümmer, dass wir seltener merken, wann unsere Leistung trügt.
Die Psychologen kennen das Phänomen. Sie nennen es Processing Fluency (PF). Heißt im Kern: Was sich leicht und reibungslos anfühlt, wirkt auf uns richtiger und besser begründet. Auch wenn es falsch ist. Oder wir gar nichts kapiert haben. Man denke an Erklärvideos: Man schaut sie und fühlt sich danach wissend, gerade bei komplexen Dingen. Aber wenn man das Thema später erklären muss, wird es dünn. Das ist als Explanatory Depth (ED) bekannt.
KI hat diesen Effekt und potenziert ihn. Die Ergebnisse wirken perfekt, die Analysen super gerechnet, die Texte sind rund und ohne Fehle.r
Früher sagte meine innere Stimme: "Ich kann es nicht erklären, also verstehe ich es nicht." Heute sagt sie: "Ich habe die Erklärung gelesen, also verstehe ich es.“
Bisher nahm unser Gehirn die Fluency als Signal für Qualität. "Da steckt viel Arbeit drin", sagte die Stimme. Aber jetzt, wo alles gut ist, verliert das Signal seine Funktion. PF + ED = OH JE !
Das "Verrückte" Upskilling und Fehlkalibrierung passieren gleichzeitig. Und genau hier liegt der Denkfehler der Debatte. Wir werden nicht "klüger" oder "dümmer". Wir werden leistungsfähiger bei schlechterer Selbsteinschätzung unserer Leistung.
Wir verlieren nicht Fähigkeiten, sondern unser Gefühl fürs eigene Nichtwissen.
Oder wie sich die Philosophen ausdrücken würden: KI beschädigt nicht unsere Intelligenz, sondern unsere epistemische Selbstdiagnostik.
Mit anderen Worten: KI verschiebt unseren Kompaß. Wir sind nicht mehr eingenordet, sozusagen. (Auch wenn Landkarten früher geostet, gewestet und gesüded waren. Aber das ist ein anderes Thema.) Jedenfalls macht uns KI zu schnell zufrieden und lässt unsere Maßstäbe bröseln. Und genau darin liegt die Gefahr.
8. Januar 2026
Perplexity.ai im Test: 22 Studien lassen den Hype bröckeln.
Das gefeierte KI-Tool verkauft Wissen und Gewissheit, liefert sie aber zu selten
Perplexity.ai wird von vielen gefeiert, weil es das liefert, was sie wollen: schnelle Antworten, sauber formuliert, mit Quellen versehen. Das wirkt wie tiefe Recherche, gesicherte Erkenntnis, großes Wissenschaftskino. Und genau darin liegt das Problem.
Es ist nicht so, dass Perplexity „Fake News“ ausspuckt. Es produziert etwas, das noch gefährlicher ist: falsche Sicherheit.
Ich habe 22 Studien zu Perplexity analysiert und auch meine eigenen Erfahrungen mit einfließen lassen.
Die Kritikpunkte zeichnen sich klar ab:
- Quellen werden von Perplexity oft nicht zuverlässig zugeordnet
- Zahlen werden genannt, sind aber zu oft nicht valide
- Synthesen klingen gut, haben aber alle Widersprüche in den Daten getilgt
Das Ergebnis von Perplexity klingen richtig gut. Aber sie sind oft nur eine Möglichkeit der Wahrheit. Gefühlte Wahrscheinlichkeiten. Oder genauer gesagt: Perplexity ersetzt strenge wissenschaftliche Logik durch wahrscheinlichkeitsbasierte, kohärent wirkende Texte. Nicht, weil es schlecht programmiert ist, sondern weil es nicht tief genug zu analysieren vermag, zu viel synthetisiert und in vielen Fällen nicht zwischen Plausibilität und Wahrheit unterscheidet.
Trotzdem (oder gerade deswegen) wirken die Antworten souverän, sachlich und wie fertige Wahrheiten. Deshalb, auch das zeigen die Studien, prüfen viele Nutzer nicht mehr nach. Die Folgen sind klar und empirisch valide: Verlust kritischer Prüfung der Ergebnisse und weniger Selbstreflektion, dafür ein übergroßes Vertrauen in die von der KI generierten Texte.
Ein wenig zugespitzt könnte man sagen: Perplexity ist kein schlechtes Werkzeug, aber es ist schlecht als Fundament für Entscheidungen.
Eine ausführliche Vorstellung der einzelnen Studien folgt später. Jetzt erstmal viel Spaß mit meiner kleinen Präsentation der Ergebnisse - gibt's hier als PDF oder als kleines "Karussell" auf LinkedIn.
7. Januar 2026
Wissens-Recherche mit KI: Schnell, klug, aber inhaltlich und methodisch blind?
Es wird viel darüber geredet, wie man mit KI-Tools Studien recherchiert und Wissen zusammenfasst. Aber :
1.) nutzen viele für eine Wissensrecherche (nur) ChatGPT, Notebook LM & Co. und selbst die besten Prompts helfen da nur bedingt weiter
2.) reichen selbst die Deep Research Möglichkeiten von ChatGPT und Co. nicht allzu weit und
3.) reichen auch wissenschaftsspezifische KI-Tools wie Perplexity, Scispace und Elicit für eine umfassende Wissensrecherche nicht aus
Aber ich kann natürlich viel behaupten. Deshalb werde ich in den nächsten Tagen eine kleine Reihe starten und an konkreten Recherchebeispielen zeigen, wo die Grenzen und Probleme eine Recherche mit KI liegen? Zugleich will ich dabei auch demonstrieren wie sehr KI unser Wissen zwar erweitert, zugleich aber einengt, wenn wir nicht aufpassen und nur auf KI-Tools zu Recherche vertrauen?
Als Thema würde ich mir mal eine aktuelle Debatte empirisch zur Brust nehmen, nämlich die Frage: Macht uns KI dumm?
Das ist natürlich selbst eine ziemlich dumme Frage, deshalb neutraler und damit besser formuliert: Welche Auswirkungen hat die KI-Nutzung auf unsere Fähigkeiten und Kompetenzen? Gibt es empirische Hinweise darauf, dass die Nutzung von KI-Tools zu einem Abbau bestimmter kognitiver oder fachlicher Kompetenzen führt. Und wenn ja, wie sind diese Daten konkret einzuordnen, wie valide sind sie und wo sind Lücken in unserem Wissen zu diesem Thema?
Das erste KI-Tool, das ich teste, wird Perplexity sein.
4. Januar 2026
Von den Lügen, die wir uns im KI-Zeitalter übers Menschsein erzählen oder
"KI macht alles seelenlos!" Warum uns dieser Satz so gut gefällt - und was er eigentlich sagt
Jeder kennt das: Man entdeckt eine Band, die kaum einer kennt. Die Abrufzahlen ihrer Songs liegen auf Meeresspiegelniveau, Auftritte gibt's keine, und im Radio wird ihre Musik auch nicht gespielt. Aber geil sind die Songs trotzdem. Oder vielleicht gerade deswegen. Jedenfalls: man liebt diese Band.
Doch dann passiert's: Die Band wird bekannt. Die Abrufzahlen steigen, es gibt Auftritte, die Radiosender gehen in heavy rotation. Es gibt neue Platten, eine Tour, die ausverkauft ist. Und geradezu reflexhaft sagt man: „Früher waren sie besser. Ihre Musik ist jetzt zu glatt. Seelenlos.“
Die Psychologen kennen das Muster: Wenn ein Teil der eigenen Identität seine Exklusivität verliert, reagieren viele mit Abwertung. Und da ist es egal, ob sich die Sache (hier: die Musik) wirklich verändert hat, denn was zählt ist, dass sich die Funktion verändert hat. Nicht mehr Ich, sondern alle hören das jetzt. Und da steigt man aus.
„Kränkung“ nennt man das. Und genau dieser Mechanismus taucht im Zuge von KI wieder auf. Vor allem wenn es ums Schreiben, Musik machen und Zeichnen geht. Bisher brauchte man – zumindest besagte das die Meistererzählung – dafür viel Zeit, Muse und Kreativität.
Doch dank KI steht die Tür zum Kunstraum allen offen. Und alle kommen rein. Und malen und zeichnen und machen Musik. Das gefällt vor allem den Schreibern, Musikern, Malern & anderen Kreativen nicht. Was völlig verständlich ist, aber nichts an der Sache ändert: man ist gekränkt.
Aber man sagt nicht: die Akkorde der KI-Songs sind schlechter, die Kontraste der Bilder nicht fein abgestimmt, die Adjektive nicht gut gewählt. Nein, man sagt: es fehlt die Seele. Das Rauhe, Kantige: die Authentizität. Aber eigentlich sagt man: Ich bin nicht mehr Teil einer kleinen Gruppe.
KI ist der große Demokratisierer. Ein Killer der Exklusivität. Was natürlich eine Lüge ist. Aber egal. Die Kunst war jedenfalls trotz (oder gerade wegen) all der ideologischen Vereinnahmungen immer undemokratisch. Schreiben, Malen und Musizieren schien nur den Talentierten (oder sehr Fleißigen) vorbehalten zu sein. Der dahinter stehende Geniegedanke ist ein historisches Konstrukt, aber wirkmächtig. Bis heute. Als Gegenbewegung zu den als seelenlos geltenden KI-Produkten erlebt der Mensch als (angeblich) kritisch-kreativer Geist eine Renaissance.
Der Satz „KI macht alles seelenlos“ ist der gleiche wie „Die Band war früher besser.“ Es ist der Ausdruck einer Kränkung, die die Entwertung der eigenen Fähigkeiten nicht wahrhaben will. Ob die KI wirklich alles seelenlos macht, ist (mir) im Grunde egal. Es ist nicht die Frage, die ich mir stelle. Meine Frage lautet vielmehr: Wie verändert KI unser Selbstbild? Welche Zuschreibungen nehmen wir vor? Und wie viel Lüge steckt in den Geschichten, die wir uns übers Menschsein im KI-Zeitalter erzählen?
26. Dezember 2025
Statistik für Menschen, die Statistik eigentlich meiden (Teil 4 von 4)
Statistik ist heute so bequem wie noch nie - und das ist Teil der Lösung und des Problems zugleich. KI-gestützte Statistiktools wie excelmatic und julius leisten zwar in der Free-Version viel, aber ihre ganze Kraft entfalten sie erst im Abo. Es ist das bekannte Problem: KI erfordert Geld oder Zugehörigkeit zu einer Firma oder Organisation, die ein Budget dafür hat.
Auch der Datenschutz ist unklar. Welche Daten sensibel sind und welche nicht ist oft schwer zu entscheiden. Wenn ich die Tools in Hochschulen oder Firmen präsentiere, arbeite ich mit synthetischen Datensätzen. So lassen sich die Tools gefahrlos erproben. Trotzdem zeigt sich in der Praxis, dass Menschen diese und andere Tools auch einsetzen, wenn die Regeln es nicht zulassen.
Barbara Geyer hat das strukturelle Problem hinter dieser Schatten-KI-Nutzung gut beschrieben: An Hochschulen, aber auch an anderen Arbeits- und Lernorten, sind die Menschen befangen in einem Trilemma aus:
1.) Funktionell schwachen eigenen KI-Systemen, die datenschutzkonform sind
2.) kommerziellen, leistungsstarken KI-Tools, die datenschutzrechtlich umstritten und z.T. auch teuer sind und
3.) fehlenden Vorgaben seitens der Arbeitgeber + Bildungseinrichtungen
Das Trilemma lässt sich nicht auflösen. Aber die Schatten-KI-Nutzung blüht auch, weil vielerorts Experimente mit dem Schlagwort „Datenschutz“ von vornherein verunmöglicht werden. Dabei ist DSGVO-Konformität kein Label, sondern das Ergebnis eines Prüfprozesses. Doch geprüft werden die Tools auf ihre DSGVO-Konformität oft nicht.
In diesen Zwickmühlen agieren auch die Statistik-KI-Tools. Sie machen zwar vieles leichter, aber sie agieren auf einem Feld, das von Unsicherheiten und Unkenntnis geprägt ist. Was also tun?
Ich selbst setze auf sensibilisieren, ausprobieren und gemeinsam über die Erfahrungen und Ergebnisse diskutieren. Auch wer keine Ahnung von Statistik hat, kann die Ergebnisse durch Einsatz mehrere Tools vergleichen, kann das Tool oder den Kursleiter fragen, was eine Regressionsanalyse, wie sich Mittelwert und Median unterscheiden usw.
Meine Erfahrung sagt, dass die Nutzung dieser Tools den Einstieg in Statistik erleichtert. Sie regen zur weiteren Beschäftigung an und bringen neue Erkenntnisse und Zugänge, nicht nur zu Daten, sondern zu Wissen und dem eigenen Fach und Arbeitsumfeld allgemein. Es muss "nur" fachkundig begleitet werden.
Wie geht ihr damit um? Kennt ihr Tools wie julius, excelmatic oder die Datenanalyse-Agenten von Mistral. Und wenn ja, nutzt ihr sie? Und wenn ihr sie nicht nutzt, woran liegt es? An Unkenntnis der Tools, Unsicherheiten wegen Datenschutz, weil ihr lieber auf die tradierte Statistikausbildung setzt oder weil ihr den Ergebnissen der Tools nicht traut? Ich bin gespannt, von euch zu hören.
25. Dezember 2025
Statistik für Menschen, die Statistik eigentlich meiden (Teil 3 von 4)
Statistik hatte bisher ein Imageproblem. Sie galt als knochentrocken und kompliziert, der Horror für Geisteswissenschaftler, Medienmacher & Marketingleute.
In diese Lücke stoßen KI-Tools wie julius.ai, excelmatic.ai und Co und versprechen Abhilfe. Und auf der Oberfläche der Ergebnisse liefern sie auch: statistische Analysen, Grafiken, Auswertungen. Doch je bequemer die Statistik wird, desto größer wird die Versuchung, sie nicht mehr verstehen zu müssen. Nicht Deskilling, sondern Gar-nicht-erst-Upskilling. Das ist ein generelles Problem, das KI in Hochschulen erzeugt.
Bisher scheitert Statistik jedenfalls nicht nur an fehlenden Mathekenntnissen, sondern auch und vor allem an Einstellungen und an der Frage, wozu um alles in der Welt man sich das antun soll. Und diese Frage stellen sich vor allem Geisteswissenschaftler, Medienmacher und Marketingleute.
Eine aktuelle Meta-Analyse (s.u.) von 29 Studien mit 5.000 Teilnehmern zeigt: klassische Statistikkurse bringen nichts. Die Leute lernen ein bisschen Statistik, bekommen dafür einen Schein – und ignorieren das Gelernte danach so lange, bis sie alles wieder vergessen haben. Oder sie können es in Studium und Beruf nicht anwenden, was denselben Effekt hat.
Das zeigt sich vor allem in den Geistes- und Gesundheitswissenschaften, also genau dort, wo Statistik oft kaum Platz hat und als modernes Übel gilt. Und warum: Weil der Mehraufwand als zu hoch empfunden wird im Vergleich mit dem, was bei rauskommt.
Und genau da kommen die KI-Tools ins Spiel, denn Statistik wird damit scheinbar leicht. Doch ein Risiko bleibt, denn das Verständnis für Zahlen und Analysen wächst nicht. Mehr noch: der Automation Bias greift jetzt. Heißt: Menschen tendieren dazu, automatisierten Systemen übermäßig stark zu vertrauen. Was die Statistik-KIs sagen klingt super, scheint rund, sieht dazu noch grafisch gut aus. Wird also stimmen.
Tut es in den meisten Fällen auch. Aber in welchen nicht? Wie kann man das prüfen, wenn man keine Ahnung von der Materie hat? Indem man die Ergebnisse mehrerer Tools miteinander vergleicht? Das wäre ein Ansatz, aber wer macht das? Kaum jemand.
Ein weiteres Risiko betrifft den Code unter der Haube: die Black Box, die wir alle immer vergessen. KI-gestützte Statistiktools generieren intern Python- u.a. Code. Aber machen sie das auch gut? Für julius.ai zeigen Studien, dass es funktioniert. (siehe Teil 2) Bei anderen Tools fehlen diese Daten noch.
Wie also weiter? Und was generell tun? Darum wird's im vierten und letzten Teil gehen.
Quelle: Pascual et al. (2025). Attitudes of University Students Toward Statistics as a Pathway to Data Literacy: A Meta-Analysis. Journal of Statistics and Data Science Education, 1-18.
https://doi.org/10.1080/26939169.2025.2475765
23. Dezember 2025
Statistik für Menschen, die Statistik eigentlich meiden (Teil 2 von 4)
Viele Menschen, die wegen fehlender Statistik-Kenntnisse bisher keine Daten auswerten konnten, können es durch spezielle KI-Tools jetzt. Die Folgen sind vielfältig und alles andere als trivial:
Geistes- und andere Wissenschaftler sind nicht mehr nur auf Texte angewiesen, sondern können auch Zahlen und große Datenmengen (und die gibt's) für ihre Analysen nutzen. Das vergrößert nicht nur den methodischen Werkzeugkasten, sondern auch die Art der Fragestellungen.
Das gleiche gilt für all jene, die irgendwas mit Medien machen, ihre Budget-Brötchen im Marketing backen oder sich in tausend anderen Bereichen durchwursteln. Sie alle können jetzt "Statistik machen".
Und siehe da: Die Analysen ergeben oft neue Einsichten und schaffen Verbindungen, wo bisher keine zu sehen waren. Doch da ist noch mehr: Weil das alles so schnell geht, profitieren auch jene, die sich mit Statistik zumindest grundlegend auskennen. Denn jetzt können auch kleinere Arbeiten, für die eine quantitative Analyse bisher zu viel Aufwand war, mit statistischen Analysen angereichert werden. KI erlaubt es hier ganz konkret, Kenntnisse zu skalieren.
Zudem machen die mitgelieferten Visualisierungen die Ergebnisse leicht kommunizierbar – nicht nur in der Wissenschaft und im Arbeitsumfeld, auch in der Öffentlichkeit, gegenüber Medien und Interessenten aller Art.
Auch sterbenslangweilige Aufgaben wie das Filtern und Bereinigen von Daten können jetzt automatisiert werden. So bleibt mehr Zeit für die eigentliche Arbeit (oder ein paar entspannte Stunden im Büro).
Jetzt fragen Sie sich: Und wie gut sind die Tools?
Meine anekdotische Evidenz aus eigenen Analysen und meinen Workshops in Unternehmen und Hochschulen sagt: ziemlich gut. Inzwischen gibt es auch erste Studien zu einzelnen Tools, z.B. zu julius.ai (Ich sollte die Leute von Julius AI nach einem kostenlosen Abo fragen 😊) Jedenfalls haben Forscher julius für statistische Analysen genutzt und ein paar Normalitätstests und Varianzanalysen durchgeführt, um die Verarbeitung quantitativer Daten zu testen. (Nebenbei bemerkt: Ich nutze julius auch qualitativ, wenn in Datensätzen neben Zahlen Texte in Form von Kommentaren vorkommen – und es funktioniert gut).
Die Studie von Chang (siehe unten) kommt jedenfalls zu dem Schluss: „dass Julius AI über außergewöhnliche Analysefähigkeiten verfügt [...] und sich als geeignetes Hilfsmittel für Forschende in quantitativen Studien eignet.“
Das alles klingt gut. Sehr gut sogar. Der Sound der Demokratisierung. Aber das ist nur die halbe Geschichte. Die andere Hälfte kommt in Teil 3 – das heißt: wenn ich die Weihnachtsgeschenke eingepackt habe 😊
Quelle: Chang, Yu-Chin: Applications of AI in Educational Research Series (IV): Application of Julius AI in Data Analysis and Visualization, in: Journal of Education Research; Taipei Iss. 370, (2025), S. 132-143. DOI: 10.53106/168063602025020370009
22. Dezember 2025
Statistik für Menschen, die Statistik eigentlich meiden (Teil 1 von 4)
oder: Ein bekanntes Problem, ein halbwegs bekanntes KI-Tool und eine unbekannte Studie
Ein Sprichwort, das gemeinhin Karl Valentin zugeschrieben wird, tatsächlich aber aus der Filmoper „Die verkaufte Braut“ stammt, besagt: „Kunst ist schön, macht aber viel Arbeit.“
Das gleiche gilt für Statistik. Das heißt: galt, denn inzwischen gibt es jede Menge KI-Tools, die einem die Arbeit abnehmen. Sie führen komplexe statistische Berechnungen durch, erklären die Ergebnisse in aller Breite und Tiefe und visualisieren sie in jeder erdenklichen Form.
Das ist nicht nur schön anzusehen, sondern hat auch was von der vielbeschworenen „Demokratisierung durch KI“, schließlich haben viele Menschen keine Statistikausbildung. Selbst grundlegende Kenntnisse sind Mangelware. Auch unter Akademikern. Die meisten Menschen begegnen statistischen Berechnungen wie der Bedienungsanleitung eines neuen Druckers: man ahnt, dass man sie besser lesen sollte, überfliegt ein, zwei Absätze – und wirft die Anleitung aus Frust in die Ecke, in der Hoffnung, dass es auch ohne geht.
Für gewöhnlich geht’s dann nur schief – und genau hier kommen die KI-Tools ins Spiel, denn die versprechen, dass jetzt nichts mehr schief gehen kann. Riesige Zahlenreihen, Excel-Tabellen – alles kann mit natürlicher Sprache analysiert und ausgewertet werden. Und das wird (zumindest von einigen) auch getan. KI-Tools senken die Hemmschwelle: Statistik wirkt weniger bedrohlich. Man kann „Statistik probieren“ ohne zu scheitern - und wirft Excel-, SPSS-, Python und andere (Hand)Bücher mit sieben Siegeln getrost in die Ecke.
Das Schöne ist: durch dieses natürliche, dialogorientierte und fehlertolerante Arbeiten wird Statistik lernbar, denn die Tools erklären, was sie tun und wie die Ergebnisse zu bewerten sind.
Die entscheidende Frage lautet aber nicht, ob diese Tools bequem sind (das sind sie), sondern ob sie wirklich was taugen?
Im Folgenden gibt es paar Antworten. Und einen kleinen „Transparenzhinweis“ vorweg: Meine eigenen Statistikkenntnisse würde ich als ganz gut beschreiben – für einen studierten Geisteswissenschaftler. Für einen Hardcore-Soziologen sind sie gewiss ausbaufähig.
Ich selbst nutze für Statistik, Datenanalysen und Visualisierungen vor allem julius.ai, greife aber auch gern auf Excelmatic (Neu Gls), einen (getunten) Datenanalysen-Agenten von Mistral AI und ein paar andere Tools zurück. Wenn's sensible Daten sind, ist Orange Data Mining eine gute Option.
Durch den parallelen Einsatz kann ich Ergebnisse vergleichen und mich dort, wo meine eigenen Kenntnisse an ihre Grenzen kommen, durch den Vergleich absichern, nachfragen, gegenchecken.
Aber was bringen diese Tools nun? Wie sehen die empirischen Erkenntnisse dazu aus? Das steht in Teil 2...

